If you work in the tech industry, I bet you have heard the crazy story of the XZ backdoor. Long story short, an open-source contributor known as Jia Tan contributed to the XZ library. After spending more than two years gaining the trust of the original author, that person (or persona) patched the software with layers of obfuscation and batch scripts extracted from seemingly harmless testing binary files. Eventually, a backdoor was injected into sshd, allowing the attacker to execute remote code. If you are interested in the story, you can read more about it, you can read the following articles:
The backdoor was discovered by a principal software engineer working for Microsoft who happened to be testing PostgreSQL performance and noticed abnormal CPU usage after updating his Linux system. More importantly, he looked into why that was and found that backdoor.

Tom from Tom and Jerry with title: Notices 500ms delay, sus. From this tweet originally.
Not as intensive as XZ backdoor story, but today, I would like to share my story of how I found CVE-2019-13132, a critical security vulnerability with a CVSS 3 score of 9.8 in ZeroMQ, primarily because of pure luck, and also my two cents about this xz backdoor event.
Back in time
In 2019, I worked as a software engineer with Niantic’s augmented-reality team. The AR team builds some services relying on ZeroMQ, a library with different messaging queue patterns that act similarly to the BSD socket. I was in charge of designing and building the authentication mechanism for ZeroMQ-based connections. As a software engineer, I am lazy, so I always love to reuse existing tools as much as possible. That’s when I found out about CurveZMQ, a protocol extension on top of ZeroMQ designed to authenticate ZeroMQ connections based on Elliptic Curve Cryptography.
I didn’t know much about Elliptic Curve Cryptography at that time. As an engineer, using something I don’t understand is always scary. I also will only be able to use most of it if I truly understand how it works. That’s why I decided to take the chance to learn how Elliptic Curve Cryptography works. I spent some time learning how it works but found very few articles on the internet explaining it well; that’s why I published Elliptic Curve Cryptography Explained back then.
CurveZMQ greatly helps authenticate the connection and establish an encrypted channel between peers, but my job also includes checking an authentication token issued by another server to see if the access grant expires. Once again, I am not a big fan of rebuilding the wheel, so I then looked into CurveZMQ documents and found the metadata field in the protocol. It turns out I can put some arbitrary key-value data into the authentication payload as the metadata.
Awesome! That’s all I need 😄
But I wondered what the upper limit of metadata size is. If we extend the authentication payload in the future, would it still work? So, I read the source code to find out.
Reading the source code and find out
By reading the source code, I realized that the incoming data was put into a fixed-size static buffer in the stack, and the payload was decrypted into another fixed-size buffer. There’s no boundary or size check.
Wait, could it be a stack overflow bug? 🤔
I quickly wrote a piece of code and fed a ton of data into the metadata field when connecting to a CurveZMQ socket. See how it goes. And boom, it crashed.

Blow my mind Gif meme
Wait a second, did I just find a security vulnerability in ZeroMQ? 🤯
I can’t believe that’s real because I have never won a lottery ticket. I thought I must have made a mistake there, so I set up a debugger to trace the code step by step and asked my co-worker to walk through the code with me. And yes, we confirmed it was a real stack overflow security vulnerability in the code I had just discovered.
Patch and disclose
We quickly patched the bug internally and got permission from the employer to disclose the bug to the ZeroMQ community. I tried to find the GPG key of the ZeroMQ maintainers but could not find one, so I opened an issue in the GitHub repository and mentioned that I found a security bug and would like to contact the maintainers confidentially. After getting their contact info, I shared this finding with them. We discussed and decided to roll out the patch for a week before we disclose the reproducer. Very soon, the ZeroMQ maintainers created a patch and rolled out the new release to all major Linux distributions.
Seeing the open-source community move quickly to patch a security vulnerability like a clock was surreal. I am not a security engineer. I am just a software engineer with a decent understanding of software security. I have never looked for any open-source software specifically for security vulnerabilities. It was just pure luck that I was looking into the source code for that particular feature, as I needed to do my job. Regardless, I am proud of what I found, and it made the open-source project I love more secure. Reading the XZ backdoor saga reminds me of that and made me wonder what this means for the open-source community.
As an open-source author
I have published a few open-source projects in the past, some of which have gained some traction. For example, Embassy is an embedded HTTP server library written in Swfit, mainly for iOS UI testing and API mocking. I built it while working for Envoy in 2016, and people still use it today. I have another pet project, Avataaar Generator written in TypeScript with React, which became one of the most popular avatar generators on the internet. I later open-sourced it.
It is rather sad to see how the original XZ maintainer burned out and was pressed into that position by the attackers. I understand that the code you wrote was like your brainchild. You want to take care of it as best as you can. However, I also want to remind myself and other open-source authors that we all have our own limits. Here’s what I think.
I owe you nothing
There are many reasons we love open-source and want to contribute to it. Be it self-promotion, or you just enjoy seeing other people find the software you built useful.

Walter White from Breaking Bad saying: I liked it. I was good at it
But at the end of the day, we still have our own life outside of the internet. While I hate to say this because I care, most open-source work is voluntary, and I owe you nothing. I spent my time or my employer’s time working on it and making it free for everybody to use it. I am not obligated to the users’ demands. If anyone thinks they are entitled, I recommend listening to this song with the loop on and enjoying their day.
AI-generated sad girl with piano performs the text of the MIT License pic.twitter.com/h5wdMuNUdm
— Riley Goodside (@goodside) April 4, 2024
Less is more, is this feature really needed?
As a software engineer, it almost seems like our job is just to add more lines of code. The more lines we added, the more productive we are. The more features our software is, the newer the version is, the better. But is it true?
I think removing code while keeping a sensible set of features and having the clear goal of software in mind is equally important as adding new code. As for open-source, I always ask myself why I should open-source the software I built. Take the Avataaars Generator pet project I had, and it was mostly only because I thought people might find a few tricks I used there interesting and could learn something from it. I had no intention of making it an evolving project. Therefore, when I see requests to upgrade the React version and rewrite it with hooks, I just ignore them.

Cat at Dinner Table meme
Sometimes, I see a new feature request come in. I always ask why this feature is needed. Is there a better way to do it instead? For example, I saw a feature request for adding a check argument like Python’s black code format for my beancount-black Beancount code formatter project. I can finish this feature in just 10 minutes or so, but instead, I asked the user why this is needed. It turned out the user wanted to use it in git’s pre-commit hook and abort the commit when the file changed. Actually, a tool called pre-commit is supported by beancount-black. After explaining, the user was happy with the pre-commit, and the issue was closed.
Always be curious and read the code
Being curious is always a critical quality of a good software engineer. If we don’t keep asking questions, many issues, like the XZ backdoor or the ZeroMQ exploit, won’t be found in the open-source community. I always learned the most when I got down the rabbit hole.

A rabbit kicking people into a hole
Reading source code is a great way to go down the rabbit hole and learn how the software works. As software engineers, we are extremely lucky. For other types of engineers, there are fewer open-sourced materials. Reading code is underrated, and many software engineers don’t understand how and why they should read it. Reading code is much harder than writing code because writing code translates your thoughts into code, and reading code is the opposite. There could be so many different intentions in my mind, and I have so many ways to write it. Without me saying it out loud, it’s hard to guess what’s in others’s minds.
Unfortunately, it’s funny that in the era of AI-assisted coding, writing code is easier than ever, but reading code is even harder because now we have to read code generated by AI. For example, some opportunists use AI-generated text plus code and submit security vulnerability reports to try their luck.
Surely, time is limited, and not all source code is worth reading, but there’s no shortcut. You can only learn what’s good and what’s bad by reading enough of the code. We should encourage people to read code. Maybe next time, if you ever wonder how open-source software works, you can try to read it and learn a few tricks from it.
Valgrind, fuzz test, sandbox, and eBPF
Interestingly, the attacker did a few things while preparing for their backdoor:
Valgrind seems to play an essential role as an obstacle for the attacker. As the attacker has been working hard with the Fedora maintainer to fix Valgrind issues, the engineer who found the backdoor also noticed some Valgrind issues. As far as I know, Valgrind is mostly used to detect memory access violations. I am curious why the backdoor cannot work in a memory-safe way, and it has to cause issues with Valgrind.
I guess they were using some operations for obfuscation purposes, which Valgrind treats as less memory-safe, which has caused violations there. Such as loading data into a memory section marked as data but executing them as code? I wonder if we can put more code under constant Valgrind testing, making it way harder for a backdoor like this in the future.
As for the fuzz tests, some claimed that the purpose of disabling ifunc in Google’s oss-fuzz tests was to avoid the fuzz tests detecting the backdoor. However, the project maintainer claimed that it wouldn’t be able to detect the backdoor. If that’s the case, I guess the attacker just wants to be extra cautious and also gain some trust.
Disabling landlock is more interesting because, as far as I know, the backdoor was injected into the sshd process with ifunc while the xz library loaded via systemd. Landlock is mostly for sandboxing file access. The remote code execution is supposed to be done by sshd instead of any standalone XZ process. Then, why disabling landlock is needed? I guess the attacker is clearing the obstacle for their following moves. They may not need it right now, but it could be for their future backdoor patch. It’s also possible that they prepared multiple paths for the backdoor to work but eventually didn’t choose it.
On the bright side of this backdoor saga, the attackers going the extra mile to disable them gave us a hint of what could be an obstacle for an attack like this in the future. I wonder how sandbox technologies such as Seccomp, landlock, and App Armor could play a role in stopping or at least making the attacks much more difficult in the future (probably not in the xz backdoor’s case). I am also interested in learning how new technology, such as eBPF, can help us detect suspicious behavior like this much more quickly in the future.
Economics of wild-caught exploits vs. farm-raised exploits
One interesting aspect of this event is to think about it from an economic perspective. We know one can sell an undisclosed critical security vulnerability for up to a few million dollars. Such as on Zerodium:
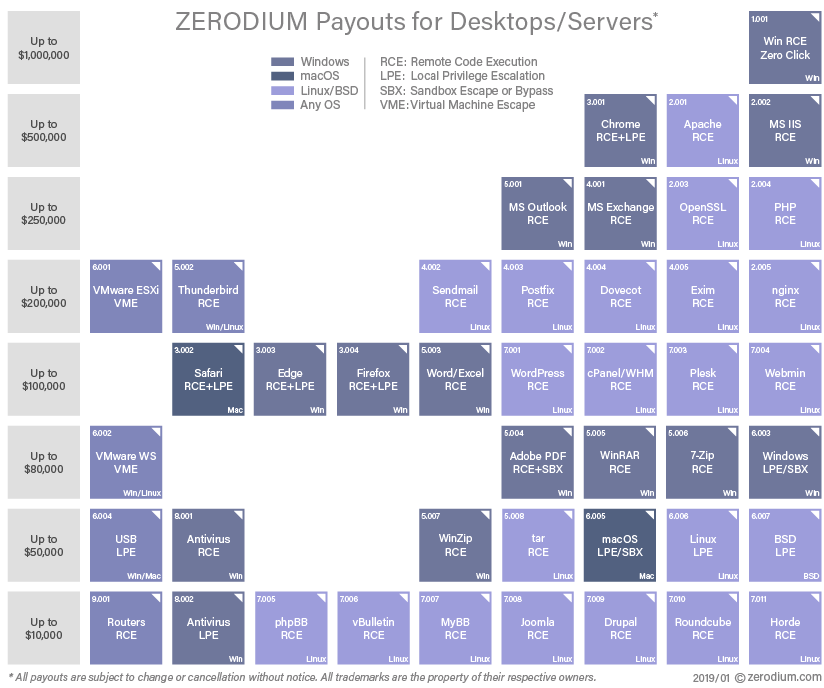
Zerodium price table for desktop/servers
Because these zero-day exploits are like wild-caught seafood, some are rare and hard to find, so the price is higher. But what if instead of buying them on the market or catching them in the ocean, we farm-raised them ourselves? That’s probably what the attackers were thinking.
It’s tough to estimate the worth of an exploit. It depends on who the buyer is and the exploit itself. I am not an expert in this area, but let’s assume there’s a zero-day exploit in sshd that can do exactly like the xz bug known to someone selling it for 1 million USD. The same 1 million USD can pay software engineers like Jia Tan to infiltrate the open-source community, gain trust, and bake backdoors in a few years. It seems like a good deal to the attackers as long as they have patience. However, only this time did they fail, and the whole investment in this project went down to nothing.

The Joker from Dark Night move burns money and said: It's not about money. It's about sending a message.
Provides “farm-raised exploits” that are way cheaper than wild-caught organic exploits. There will only be more attempts like this. Actually, Jonathan Blow have already predicted this years ago:
Final thoughts
Open-source is beautiful. It’s really hard to explain.
Do you mean a bunch of nerds who don’t really know each other in real life but work like clocks to build the most sophisticated software in the world through the internet and make it free for people to use 🤯?
Here’s the visualization of Git development history.
Nowadays, open source is no longer just a hobby of computer nerds. Billions and billions of devices run open-source software. In the internet era, this is more true than ever:
Knowledge is power
Unfortunately, when the stakes are high enough, bad actors will always try to take advantage of us. While the implications of bad actors like “Jia Tan” are scary, nobody wants to make participating in open-source communities like playing among us after all.

Video game Among Us an impostor killed another player
We are all human beings. We all make mistakes, and nobody should take the blame for this event, probably except the bad actors. There’s no silver bullet to solve this problem. The more important thing is how the community moves forward as a whole and thinks about what we learn from this and what we can do to make it more difficult. As long as there’s a benefit to gain, bad actors will always try to pull it.
The above is my story of finding a security bug in ZeroMQ and the two cents about the xz saga. What do you think we should do to prevent this from happening again?