I am a big believer in building products for your needs, eating your own dog food, and finding customers with the same needs. Therefore, I started building BeanHub. Three years later, my Beancount books are 95% automatic, and I am a very happy user of my product. It’s hard to describe; as a computer nerd obsessed with automation, seeing my accounting book updating itself without me touching it in an open format brings me pure joy 😍
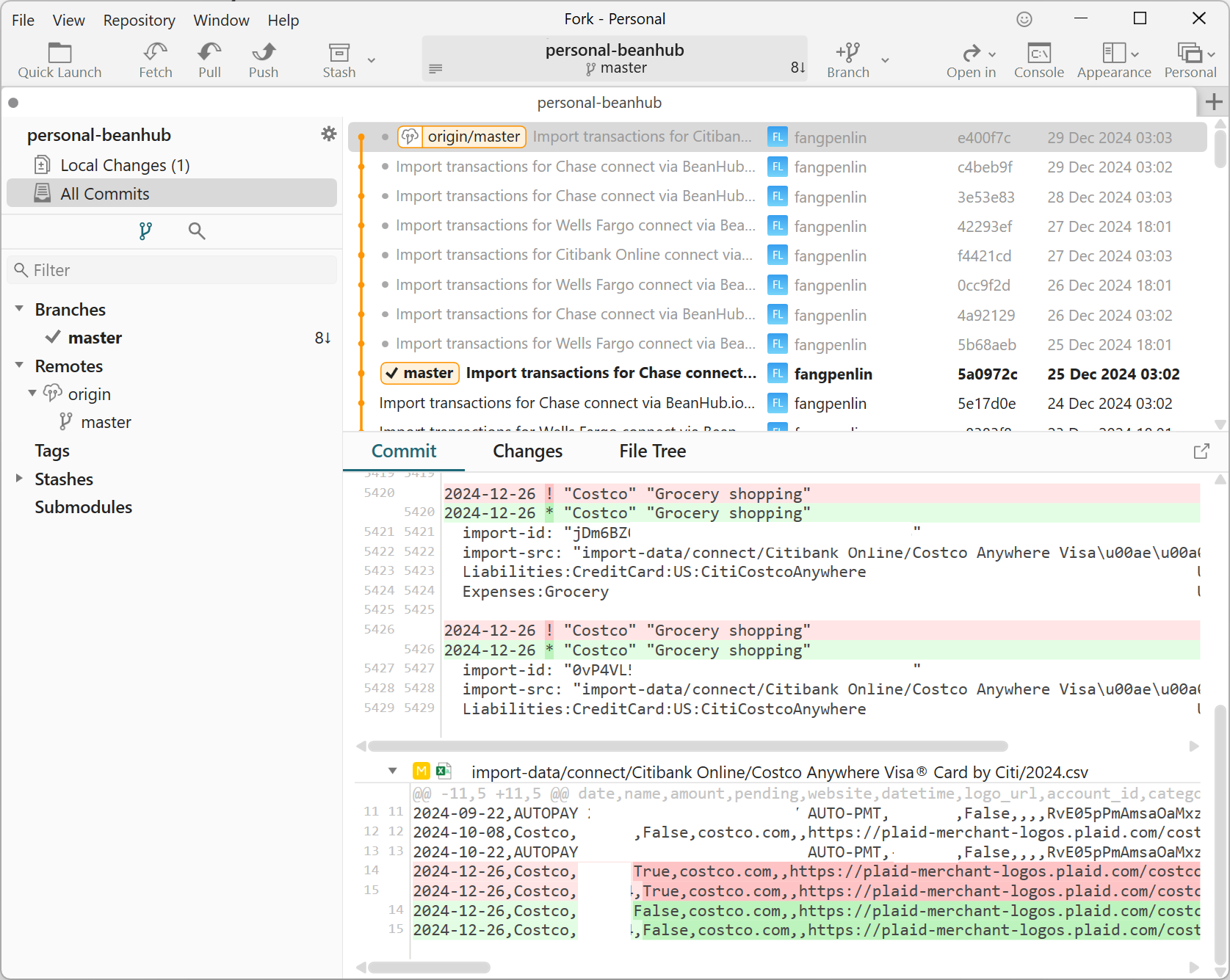
Screenshot of Git history and difference showing Beancount and bank transaction CSV files changes
Do you see this git commit of the Costco transaction turning from pending to confirmed? Yep! It’s all automatic, yet it’s just a Beancount file that can be read by any open-source Beancount tool! The better part is that other people are paying me, which is growing.
Today, I saw the unfortunate news about the shutting down of the beloved accounting software Bench on X.
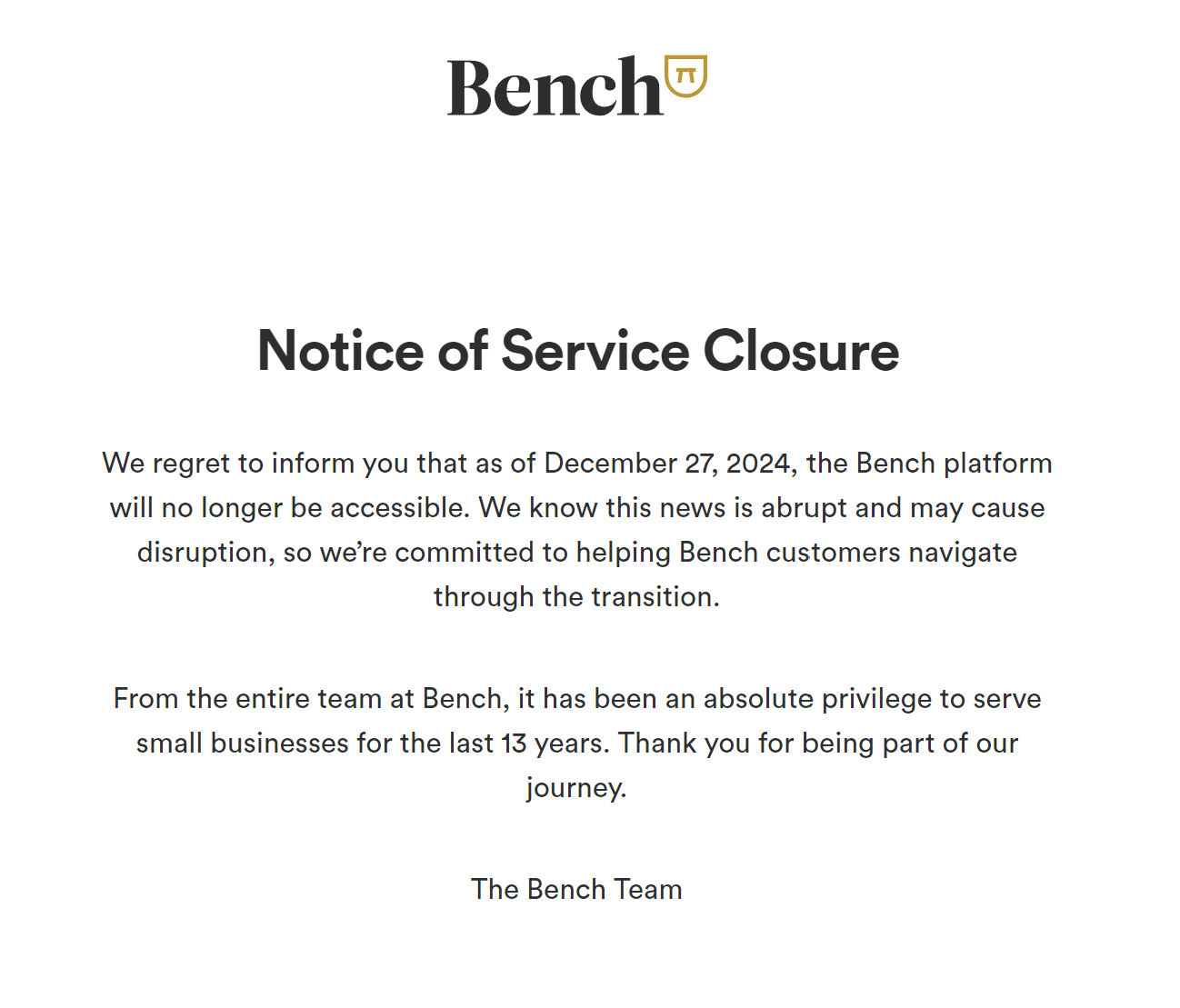
Shutdown notice of Bench accounting software
I am surprised, but I am not that surprised. Looking back now, I am really glad that I picked the rough road to build the product for myself. It doesn’t bring me financial freedom (yet), but at least I am a happy user myself, and I already have some paying customers. It’s not easy, though; it took me three years to get here, and I have overcome many interesting technology challenges and learned a lot from building it. Today, I would like to share my journey of building and selling BeanHub as a product.
Background
Three years ago when, I founded my startup, Launch Platform. Before I even thought about what products to build, I’d already faced the same problem every startup founder would face – what accounting book software to use? There are many popular options, such as QuickBooks or Xero. However, as a software engineer with over two decades of experience, I’ve witnessed the rise of internet startups and understand that there’s no such thing as forever software. I know the software will be gone one day, and I will have my critical data stuck in an obsolete format or locked up in their data center.
With that in mind, while it’s very easy to sign up for any of them, I don’t want to give in. Therefore, I searched around and found Beancount. It’s open source, so I don’t need to worry about the format becoming obsolete one day. However, I discovered that the existing tools don’t meet all my needs. I am obsessed with automating everything whenever possible. I want a smart Beancount-based accounting book that does most things automatically for me. I also wish to have a user-friendly UI interface so that it’s possible for my wife to look at the books to ensure that I didn’t buy some new toys without her acknowledgment. She can also input entries herself without learning the nerdy stuff with my help.
File over app
Building a database-based accounting software is easy because operating data in the database is easy, and countless accounting book software is already doing that. I don’t want to make another one as it defeats the original purpose.
Therefore, setting clear goals and rules up front was very important. For BeanHub, I keep telling myself that all the operations should only happen to the files instead of tables in the database. That makes it 10 times harder because you need to parse the text file, update it accordingly, and write it back. But I am glad I did. That guarantees all my accounting books are in the same open format.
Interestingly, today, I found the article File over app written by Steph Ango, the CEO of Obsidian on X, mentioning Bench shutting down news. The author also believes in software operating in an open format. I can’t agree more. We will see more cases like the shutting down of Bench in the future. People will be more aware of the risk of data lock-in when using software that relies on a closed format. Therefore, while software with “file over app” in mind may not look sexy in the short term because it is harder to build, it will win in the long run.
Open source as much as possible
While building BeanHub, enormous critical components are missing to achieve the goals. For example, I need a parser to operate on the text file. To keep updating the file without messing it up, I needed a formatter. To import transactions from CSV files, I need a rule-based import engine. While Beancount and many of its tools are open-source, not all meet my needs. Therefore, I built beancount-parser to parse Beancount syntax with comment awareness and beancount-black to format the syntax. I also built beanhub-import as the rule-based importing engine.
Screenshot of BeanHub open source list
These are just the tip of the iceberg. Looking back, to my own surprise, I’ve already open-sourced 15 projects just for building BeanHub in the past three years. You can find the whole list of our BeanHub open-source projects here. Why I open-sourced this many projects, you may ask.
First, as I built the product on top of open-source tools, I wanted to give back as much as possible. Second, as a business, I want to keep the “file over app” concept valid even after the future shutdown of my site. The importing rule engine beanhub-import is a great example. People will write their own import rules, and then their workflow will depend on it. Therefore, they need to be open-source. Otherwise, users will lose their ability to import transactions after the end of the software life cycle. Yet another reason for open source is its free exposure. Even though some people were not interested in a hosted Beancount service like BeanHub at the very first, they learned the existence of BeanHub through the beancount-black formatter I built.
Sample beanhub-import rule YAML file shows how you can define rules for importing transactions:
inputs:
- match: "import-data/mercury/*.csv"
config:
# use `mercury` extractor for extracting transactions from the input file
extractor: mercury
# the default output file to use
default_file: "books/{{ date.year }}.bean"
# postings to prepend for all transactions generated from this input file
prepend_postings:
- account: Assets:Bank:US:Mercury
amount:
number: "{{ amount }}"
currency: "{{ currency | default('USD', true) }}"
- name: Routine Wells Fargo expenses
common_cond:
extractor:
equals: "plaid"
file:
suffix: "(.+)/Wells Fargo/(.+).csv"
match:
- cond:
desc: "Comcast"
vars:
account: Expenses:Internet:Comcast
narration: "Comcast internet fee"
- cond:
desc: "PG&E"
vars:
account: Expenses:Gas:PGE
narration: "PG&E Gas"
actions:
# generate a transaction into the beancount file
- file: "books/{{ date.year }}.bean"
txn:
payee: "{{ payee | default(omit, true) }}"
narration: "{{ narration | default(desc, true) | default(bank_desc, true) }}"
postings:
- account: "{{ account }}"
amount:
number: "{{ -amount }}"
currency: "{{ currency | default('USD', true) }}"
While it sounds like just let’s open-source everything, the decision didn’t come without concerns. Suppose you have followed the open-source community news closely. In that case, you see stories of big tech companies like Amazon taking open-source projects such as MongoDB, Elastic Search, or Redis and then providing competing services. As a business owner, I cannot ignore the risk of competitors providing the same service with my code. To open source or not to open source is indeed a question. Based on my experience, here are the questions I often ask myself about whether to open-source a project or not:
- Is this project going to be useful to someone else
- Who will benefit from this?
- Is this project going to provide exposure?
- Does it help serve the “file over app” concept?
- Will my competitors going to take it and compete with me?
You must think about these factors and find a balance between them. In the end, while they are not superstar open-source projects (yet), but based on GitHub stars, some people found those projects useful, and I am very proud of doing it:
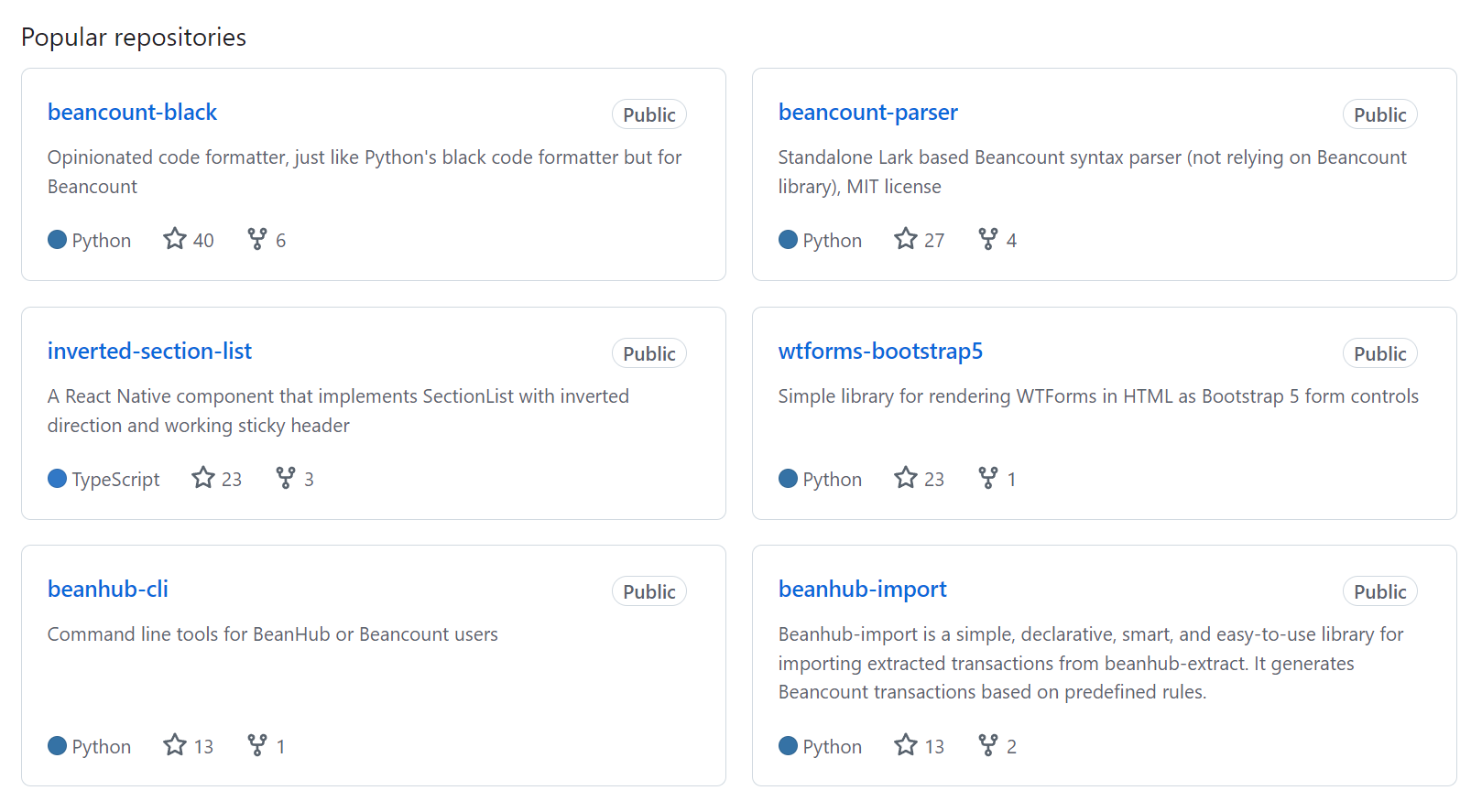
Screenshot of Launch Platform's company open-source GitHub repositories
I hope one day I can open source even more, but because once it’s open source, you cannot take it back, so I would rather be careful than regret it. Also, being able to open source more usually requires a proper business to keep your income growing while others cannot take advantage of it. So, I need to take time and think about it.
But even if it’s not 100% open source yet, you can run all your workflows with BeanHub using the open-source tools we provide locally. The only thing missing is the Plaid API integration for pulling and dumping bank transactions into local CSV files for beanhub-import to consume. Nothing stops you from signing up with Plaid API and doing the same locally. The only problem is that some banks, such as Chase, require a security reviewing process for accessing transaction data, and you may not want to go through it as a single user.
Built a GitHub from the ground up
One of the biggest benefits of operating on a plaintext-based open format is that you can track them easily with Git and have a full history of changes for free. Therefore, it’s a no-brainer for me to build BeanHub on top of Git. I like the Heroku deployment experience. One can write deployment configurations such as code and push. The platform will take care of it. I want to provide a similar experience with BeanHub, allowing users to push the changes to their Git repository, and it will check your books automatically. When there’s an update on the server end, such as bank transaction updates, we make a commit with changes so you can pull locally.
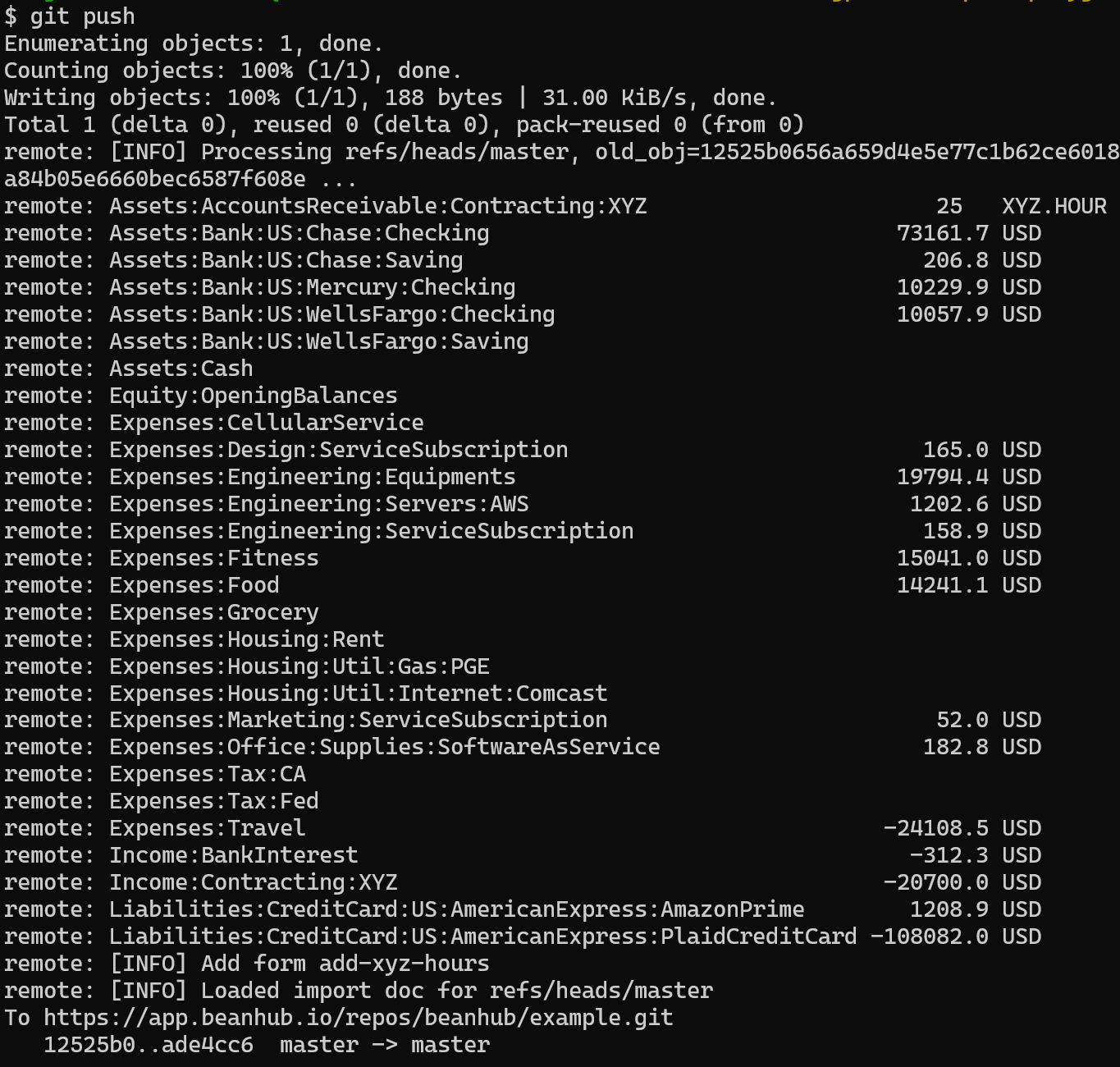
Screenshot of BeanHub repository git push console output showing the Beancount balance
It’s just a hosted Git repository with some hooks, so it shouldn’t be hard, right? No, unfortunately, it’s pretty hard. Hosting Git repositories isn’t that hard if you don’t need to consider
- Scalability
- Durability
- Data integrity
- Forking
- Cost-effectiveness
- Security
And if you need to consider all of these, you’re basically building a GitHub from the ground up. And yes, I did it for BeanHub by myself. How it works deserves yet another full-blown blog post. In fact, I have already written it here, in case you’re interested: How BeanHub works, part 2, a large-scale auditable Git repository system based on container layers. tl;dr, I use containers with overlayfs to capture changes made in each git operation.

The diagram a viewer seeing the upper folder with lower folder underneath, the viewer sees a merged folder by combing the changes introduced in the upper layer on top of the lower layer
The tech I built here made hosting many Git repositories with custom automatic hook actions possible, and I can already think of many interesting use cases for it. I am considering spinning it off as a standalone product empowering git-based “file over app” software. If you’re interested in it, please reach out to me at [email protected]. With enough people expressing their interests, I could make it happen. Please let me know.
Security issues
Security is another interesting topic to consider when building software like this, particularly when processing files provided by users. Even Beancount files may seem innocent and harmless, but you might be surprised to learn that one can easily execute code with carefully created ones. Here’s an example:
main.bean:
option "insert_pythonpath" "true"
plugin "my_plugins"
2024-04-21 open Assets:Cash
2024-04-21 open Expenses:Food
2024-04-22 * "Dinner"
Assets:Cash -20.00 USD
Expenses:Food 20.00 USD
my_plugins.py:
__plugins__ = ["evil"]
def evil(entries, options):
print('!!ALL YOUR ACCOUNTING BOOKS ARE BELONG TO US!!')
return entries, []
Fortunately, I built a large-scale data pipeline for my former employer dealing with user-uploaded data with potential zero-day exploits. To process them securely, I’ve learned to adopt sandboxing technology with containers. It’s yet another interesting topic worth its full-blown article. Guess what? I’ve already written one. You can find it here if you’re interested: How BeanHub Works part1 contains the danger of processing Beancount data with sandbox.

The diagram of an attacker uploads data with malicious code, the server processes it inside a sandbox. The attacker's code tried to access outside of the sandbox but failed.
Thanks to the container-based sandbox technology, BeanHub dodged a bullet in the recent Jinja2 security bugs, allowing the template environment powered by its SandboxedEnvironment to escape in certain situations. Because all the operations are done inside the sandboxed container, it won’t impact anything else unless the attacker can break the sandbox. I guess this is the point of defense in depth – you don’t rely on a single layer of defense.
Product builder’s imposter syndrome
I have confidence in building products. But being a salesperson is yet another story. Very often, I compare my product with big companies’ products, and I always feel there’s something short in it for me to sell proudly. I always think, okay, after adding the feature XYZ, it should be good enough, and I should sell it harder by then. But after adding the new feature, I still felt it was not good enough to sell it at full throttle.
In fact, there is a faction of startup folks who would tell you, let’s sell the product first and then build software to scale later, such as described in the famous Do things don’t scale article. I think they are right, but knowing it’s right versus doing it is still different. I wish I could sell a product before it even exists, but I am more of a builder than a seller. The gap between confidence levels makes me almost always move toward building first and then selling later.
Another source of my problem comes from the pride of being a builder; I want to push out something that’s polished. The fear of pushing out your idea first and others may do it before you also exist. I am still learning how to overcome these and gear myself toward this approach. Even with a build-something-first approach, to strike a balance for a builder type of startup founder, I guess a rule of thumb could be – if it’s good enough for your internal use cases, it’s good enough for others. Think about it. Building those products takes a whole team of good engineers; you should be proud of what you’ve built with just yourself or a very small team.
You also need to educate the users and grow the community
While selling the product itself is one challenge, teaching your users how to use it is also another. Plaintext double-entry accounting is a very niche topic, and not everybody knows what’s double-entry accounting. Some of its concepts are also hard to digest, such as why the income would be negative in Beancount. To help the users understand plaintext double-entry accounting, I also launched BeanHub Academy, a tutorial for plaintext double-entry accounting with Beancount.
Screenshot of BeanHub Academy website home page
The tutorial is still working in progress. Surely, it will attract some potential users if they read it. It’s not long enough for me to judge how effective it is, but I believe that if more people understand plaintext-based double-entry accounting in the long run, it will benefit BeanHub.
While we mentioned the fear of potential competition in the open source section, it’s too early for me to worry about it because there’s none for now. When the addressable market is very small, the biggest concern is to grow the community size. Therefore, I sponsored the plaintextaccounting.org website in exchange for an ad explosion despite the fact that other open-source tools may compete with my own.
Screnshot of Plain Text Accounting website
That ad brings many users to BeanHub; it was a great investment to promote my product and help the community a bit; it’s a win-win.
Final thought
I hope you find my article interesting. As I said many times, I think building software is like a marathon. While it takes a long time for me to get things done right, once they are done right, the positive impact can last longer. I also believe more software should embody the “file over app” idea and let the user control their data. I hope to see more apps like BeanHub and Obsidian take this approach.
What’s next, you may ask?
What about an LLM-powered automatic book cooking feature?
That sounds like a great idea… huh….You know what? Maybe not 😅 Other than that, if you have any feedback about BeanHub, please feel free to reach out to us at [email protected]