Update: This is the first article in the MAZE machine learning series. You can read other articles here:
I can’t believe I am publishing this. I’ve been thinking about Artificial general intelligence and how to build it for a very long time. Call me crazy if you want, but I have an idea of building it differently from the mainstream approach. Instead of using backpropagation hammering down on smartly handcrafted networks, I want to build a system that can produce arbitrary neuron networks based on evolving and mutating genes in a series of controlled environments. Of course, every cool approach deserves an awesome acronym name. That’s why I named it MAZE (Massive Argumented Zonal Environments) 😎:

MAZE stands for Massive Argumented Zonal Environments
I spent last week building a prototype that can generate random neuron networks based on a gene sequence. Shockingly, I haven’t even implemented the part of generating offspring and gene mutation, but some randomly generated networks I saw during the development have already shown better performance than the ones I crafted manually during the learning process.
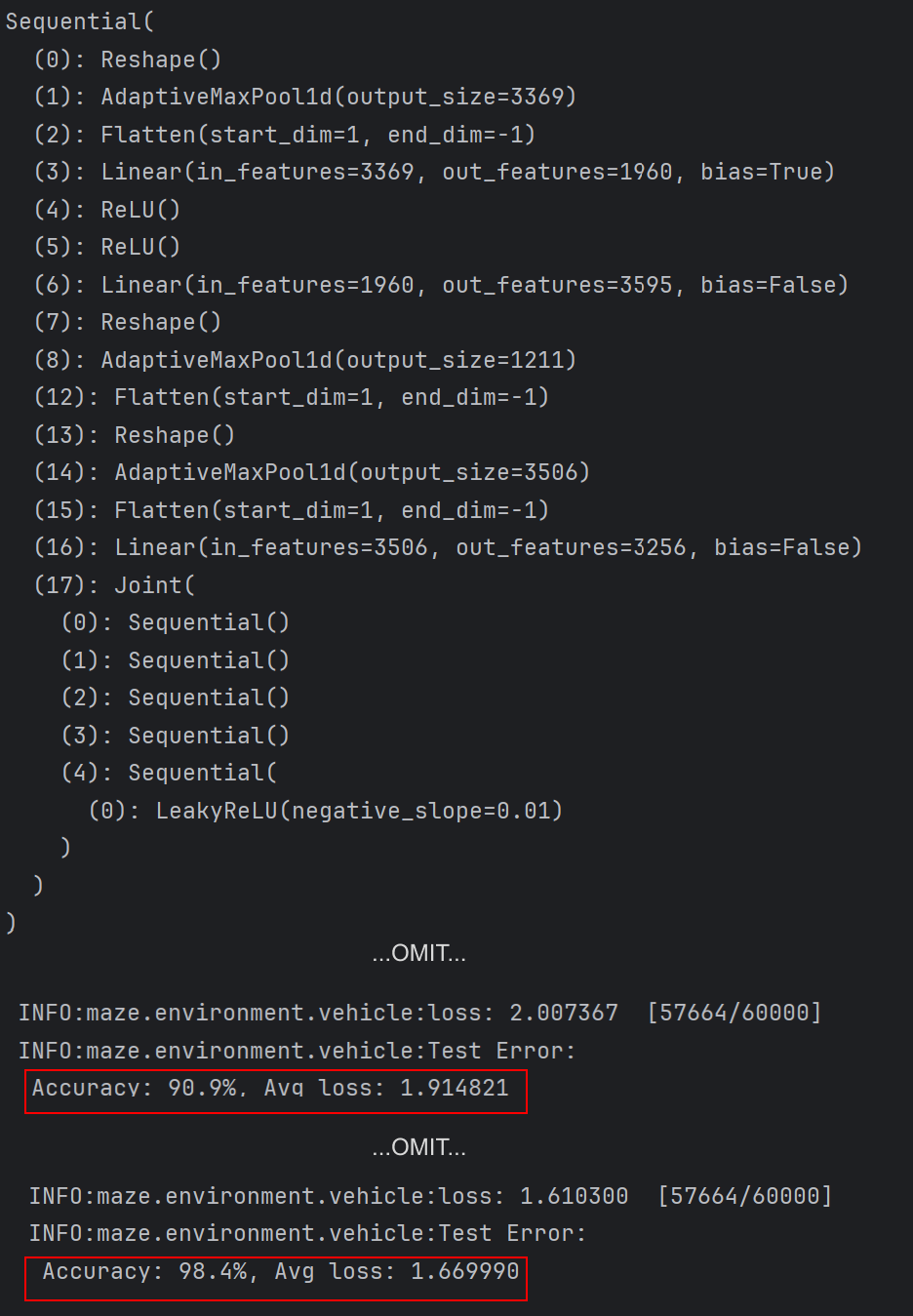
The screenshot of the maze program output log shows a very random-looking neuron network model that reaches 90.9% accuracy after the first epoch and reaches 98.4% accuracy eventually.
As you can see in the above screenshot, the randomly generated model achieved 90.9% accuracy in the first epoch and finally reached 98.4% without any manual tuning. There are multiple ways to achieve AGI, and I believe my approach could be one of them. Today, I’ve open-sourced the initial work, and I would like to share my whole idea of building AGI and what I’ve learned from it.
My allergic to AI
I used to be allergic to AI. Nowadays, everything has to do with AI. AI refrigerators, AI toilets, I mean, why not? 😂 For every short while, there will be a new hype everybody is chasing. It used to be cloud, big data, and so on, you name it.
I am a weirdo, I guess. I don’t like reading answers before coming up with my own ideas. Since I have my idea of building AGI, I don’t like reading about it. It almost feels like other people’s ideas will infect me. I also take extreme pride in the software I produce, so seeing AI-generated code is a hard pill to swallow. I still remember a few years back chatting with my coworker on a San Francisco street about AI probably taking my job in five years. While it’s still not there yet, it’s already very impressive how far it has come.
A while back, I finally decided to give it a try for solving tedious paperwork on my job. And it turned out it works great, and I kinda like it.

The "Get That Thing Out Of My Face!" meme comic by Chicken Thoughts. A bird yelled, "Get that thing out of my face," in front of a cracker. Had a bite and turned out to be loving it.
Without using it, I would probably have spent way more hours or even days solving the problem. So, despite all the hype, as long as you understand it and put it to the right use, it’s just yet another very productive tool. In the end, AI, you’ve won. I’ve decided to learn it.
Meme from the comic book "Lovesick Dead" by Junji Ito, modified by myself. A crowd yelled different trendy machine-learning terms in front of a house and climbed to the second floor, pounding the windows. And a guy opened the window on the second floor and said, "Okay! Fine! I will learn it now."
DeepSeek R1, the Sputnik 1 moment
My last memory of machine learning was about CNN (convolutional networks). I spent some time catching up with the LLM, transformer, and GPT, all the good stuff. Surely, I am not an expert yet on those matters. Funny enough, just around the time I kicked start learning it, the DeekSeek R1 was announced, and it’s open-sourced. It changed the whole landscape of machine learning overnight. Of course, there is a lot of drama about the “pet project”’s actual cost of training, the GPU they use, and whether or not they use OpenAI’s data. None of those matters. The only lesson here is that we always think we have an advantage, but it may not always be true if we let our ego take the driver’s seat.

The First Satellite, Sputnik 1, was launched by the Soviet Union on 4 October 1957. It shocked the United States because, at that time, people believed the USA was leading the space race. CC BY-SA 3.0 from Wikipedia
{kind=link}
Ironically, AI companies in the US are closed-source, and it turned out to be the one from China open-sourcing their pet project. As I am on the team USA, it’s a complicated feeling. But regardless of the saga, I admire their creativity and ability to pull it off. Doing something known to work is easy, but finding a new path is hard. I would recommend watching YC’s The Engineering Unlocks Behind DeepSeek unbias explanation video by Diana Hu to understand how it works better.

Screenshot from HBO's Silicon Valley TV show featuring its character Jian-Yang by Jimmy O. Yang.
I thought, okay, sure, I can learn LLM and know how to apply it shortly. But in the end, it’s just yet another tool. It’s like having a hammer in your hand, and then everything looks like a nail. I believe, as a software engineer, the real true competitive advantage is always the ability to learn new things quickly. More importantly, creativity is rare. The reason R1 can work is that of creativity and the ability to bring the idea to reality, which is even rarer. I am unsure if I can do anything meaningful, but I felt the urge to do something. That’s the moment I decided to write down my idea of evolving the AI model, kickstart my MAZE project, and open-source it. In other words, it would be research in public. What’s the worst case? Well, I may fail, but I will learn a lot quickly. Hopefully, maybe I can help accelerate the progress of machine learning a little bit.
First design principle for machine learning
When it comes to designing a new system, I always love to think from the very basic stuff, asking the most fundamental questions. It’s called the first design principle. The existing system always carries its own history of development. The path it took was influenced by the way the environment it was in. Like, if we think about building an Electric vehicle, the most obvious way is to think about putting motors and batteries into a gasoline car frame. Because we know it works.
The same applies to machine learning. We all know backpropagation, hidden layer, convolutional network work, and the transformer works. We always tend to use a tool that works because finding a new one is extremely hard. However, the hard part is also the source of fun. If you already know it will work, what’s the fun of it?
Screenshot from the Neon Genesis Evangelion TV anime show featuring the MAGI AI system. It shows three virtual personalities debating while the system is being hacked.
I have always been a fan of science fiction, and I have always wondered what it takes to build true artificial intelligence or even an artificial intelligence life. There’s no better teacher than the mother of nature because the system is already there, and it works magically. I am not a biologist, but I am always curious about how all these work. I’ve learned fragments of knowledge from different sources. For example, some birds rely on quantum effects in their eyes for navigation. After reading that article, I wondered if there could also be some sort of quantum mechanics in the human brain as well.
There are also other interesting questions. Such as, the human brain has 86 billion neurons with 100 trillion connections, but the whole length DNA sequence is only 3 billion pairs. Where are the initial weights and biases coming from? Some animals, like horses, can start running after they enter the world. Fishes can swim immediately, instinctively seek food, and avoid dangers without training. How it all works? I haven’t looked it up, but I have some theories.
I recall some articles that mentioned that a mother’s brain communicates with a baby’s brain in the womb. One of the purposes is to check if the baby is viable or not. I wonder if there’s also a bootstrapping process happening there to prepare the baby’s brain. Even if this could work, oviparous animals don’t share the same process, so they may need the weights and biases baked into their DNA. Anyway, a neuron network is just an overly simplified computer model; certainly, there are many things we don’t know yet, and I am probably the least qualified person to talk about this topic.
Regardless, my idea is mostly inspired by what I read and observed about how life works in nature, and I try to mimic the process on the computer.
What’s MAZE, and how it works?
First, I have to admit that The Maze from the West World TV series inspired the name MAZE. I really love the TV show 😄

Screenshot from HBO's West World TV show featuring a maze-like symbol called The Maze in the show.
Part of MAZE’s purpose is to answer a simple question: Given certain input shapes, output shapes, and good training data, what’s the best neuron network model to use?

A diagram shows the input and output layers of neurons connected to a box in the center with question marks. What would be the best model structure to use?
For all the newcomers to machine learning, we always have questions, mostly about what to use, how many, and why. If we look at the history of the development of machine learning, almost all major breakthrough milestones come after we find a new effective structure of the network. First would be the CNN (convolutional network), then the transformer. Other than that, using different specialized networks and making them work together is also a key to success. There is a lot of know-how in it, mostly based on trial and error experiences. Like, three is a good kernel size for CNN based on the experience of others in the past.
The MAZE project is trying to solve the hard problem by automating this process. Instead of manually tuning and finding the best neuron network structure and parameters, I want to generate many different genes and build corresponding models, putting them into a series of predefined environments on a large scale to see how they evolve and perform.

A diagram shows that performing agents are selected randomly pairwise, and we take their genes and merge them randomly to generate offspring. The LHS and RHS mean left-hand-side and right-hand-side, coming from common C++ function parameter naming practice for an operation involving two parties.
The high performers will be selected and matched randomly with other high performers to reproduce offspring. We will add some random mutations to ensure that agents can evolve. The most interesting part comes next. At some point, we will promote high-performing agents to enter the next environments with slightly different rules. Think it’s like Isekai reincarnation:
Goddess to agents: Congratulations! You’re the selected one and summoned into this world to fight the demon king.

Screenshot from the KonoSuba TV anime show featuring the Goddess Aqua telling Kazuma, "Your life was a short one" after his death.
Sorry, if you know what I am talking about, you’re also probably pretty nerd 🤣
The idea here is that it would be very hard for a random neuron network to perform anything good at the very beginning. Or even if they do, it would be costly. The initial environment should be very gentle and forgiving. The next environment might be slightly difficult to survive. The next one would be even harder to survive and might be very competitive. The not only differences in difficulty, but we can also introduce new challenges and mechanisms for the agent to adopt graduately.

A diagram shows a series of environments starting from easy, medium, and then hard. There are zones in that environment, and we are selecting high-performing agents from the previous environment to the next.
The idea of MAZE focuses on designing a series of environments to breed the neuron networks as we want. Think about this: there’s no way a single-celled organism can land on Mars just right out of the soup of life. At the very beginning, there’s no competition, there’s no predators. Later on, some creatures gain an edge in survival and even start consuming other creatures. Over time, life becomes more and more complex due to the rising pressure of surviving and the competition from peers. The point of MAZE is to simulate environments from easy to hard, simple to complex, and guide the evolution into how we want it to be.
So, for environments, are we just making it harder and harder? Right? Well, I think adding a bit of slacking in between would be very interesting to see a bit of diversity in survival strategy. In the peaceful era, life can go crazy with their energy, developing different strategies despite the fact that those may not be optimal at that time. And then it comes into the harsh era. It puts all of them to the test under stress. Even many creative ones might not survive the harsh environment as long as their gene is carried in a deactivated state and could be activated again later in a proper environment or remixed with the others to be helpful.

A diagram shows a series of environments starting from easy, medium, hard, medium, and finally hard again.
The intriguing part of this MAZE idea is designing different environments to achieve the desired behavior. For example, you could have one branch of environments for learning vision and another for learning motion control. Let yet another environment in between let them cross-breed or force them to work together.

A diagram shows a series of vision and motion environments starting from easy, medium, and then hard. Then, both of them connect to the integration environment from easy to hard.
These are just very fundamental examples. I believe with the proper design of MAZE environments, we can eventually evolve an AGI model. Of course, designing and building these environments is hard, but this is where the fun of it.
Accumulate survival bias
When we talk about survival bias, this picture always comes to our mind:
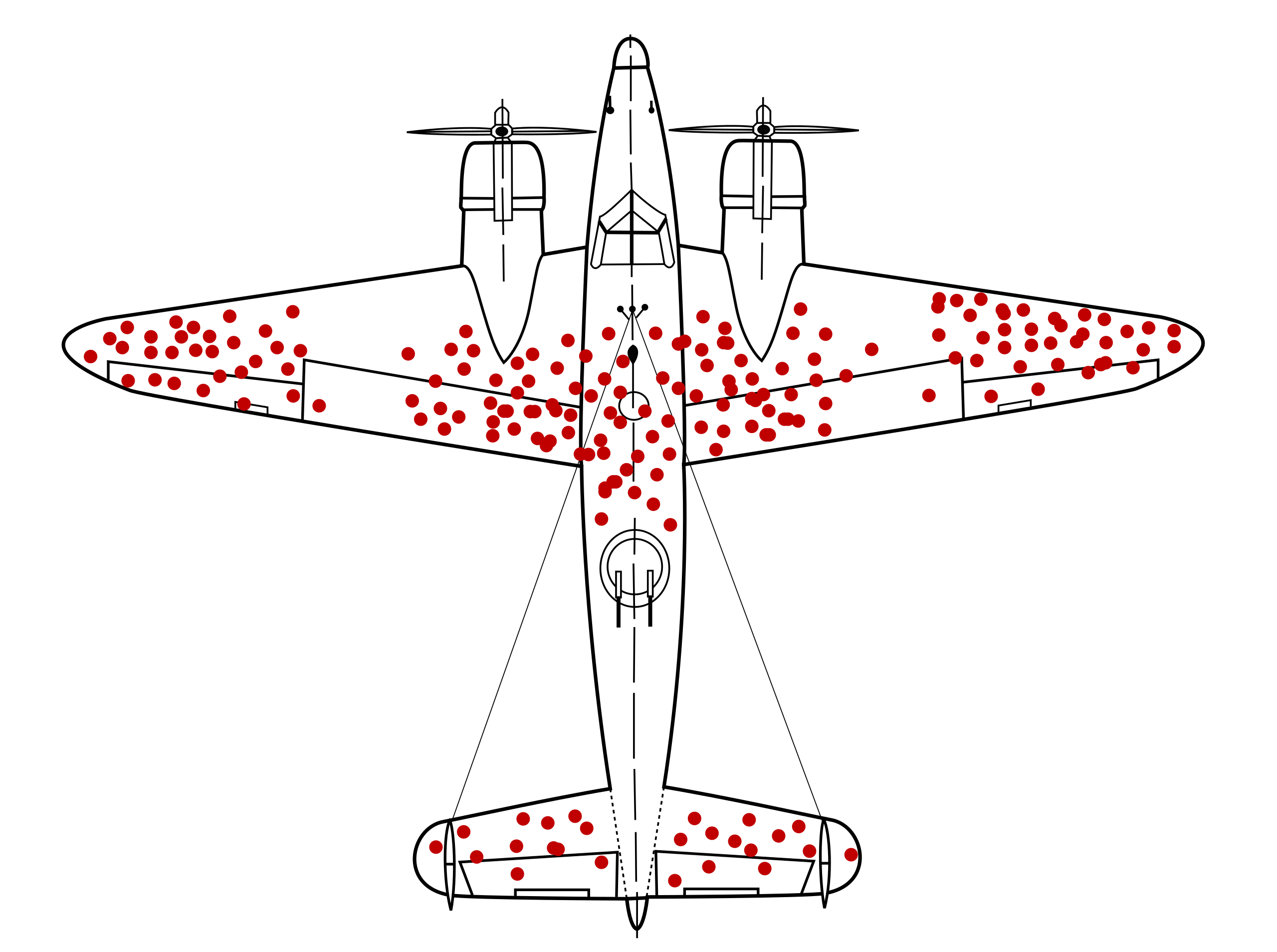
Diagram in which red dots stand for places where surviving planes were shot. This only tells you where planes can get shot and still come back to base. Survivorship bias: your only information is what has survived. CC BY-SA 4.0 from Wikipedia
{kind=link}
While I should probably come up with a proper name, I will steal it for now. In the context of MAZE, it means the advantage of surviving in an environment. In the ocean of randomness and the ability to reproduce, the agent can take advantage of anything helpful to help them survive and reproduce more. Even if it’s just a bit biased, it can accumulate over time. One of the critical design goals of MAZE is to make it possible to maintain the accumulated survival bias while still maintaining the ability to evolve and adapt.
I think, ideally, there should be some kind of library of different neuron network patterns that an agent accumulates in its gene naturally over time. From a programming perspective, it’s like a function call. In that way, hopefully, with a sophisticated gene pool, you can throw various challenges on them, and they can adapt by using their gene library quickly without evolving the same solution from the ground up again and again.
Why zonal?
As you have noticed in the previous environment diagrams, we have many zones in the same environment. Why make it zonal, you may ask? The reason why I made it zonal is because we need to allow a bit of diversity for the gene pools. If we only have one environment, the winner could easily take all. While it might be an effective solution in the early stage environment, it might actually take a shortcut so that it will lose in the long run. Making it zonal provides a bit of breathing room for agents with different strategies to survive. Their approach might not be the winning one in the early-stage environments, but that doesn’t necessarily mean they won’t win in the late stage.
Other than that, yeah, I admit that I really want to make the acronym. 😂
Challenge: design a fault-tolerant neuron network construction language
With carbon-based lifeforms on the earth, different proteins can be assembled based on the mRNA, and it will fold itself into the right shape in most cases. With neuron networks, we also need a language to represent the model to make any neuron network structure possible. Since we are seeking tiny bias in the ocean of randomness, there will undoubtedly be many errors if the system is not fault-tolerant. We built computers to be accurate. Therefore, being fault-tolerant is hard. So far, it’s the most challenging part of making it fault-tolerant.
My original idea was to have a language that directly describes the structure of neurons by neurons and their relationship with each other in a 3D environment. But since this is still a pet project, I don’t want to spend too much effort building a whole new neuron network library from the ground up, so I built most of the symbol mapping to PyTorch operations. I know that by doing so, we may lose a certain degree of freedom for the agent to form any potentially possible networks. However, I would like to start simple, see how it goes, and dig the rabbit hole later if I need to.
Okay, we have an idea of how this should work. Here are the symbols I designed for generating random neuron networks.
ACTIVATE / DEACTIVATE
The ACTIVATE and DETECTIVE symbols mimic how there could be a sequence segment in DNA but not in an active state.
I added this pair of symbols to hope it makes carrying deactivated genes possible across generations and makes it possible to reactivate in an environment of certain pressure.
The symbol works simply by ignoring all symbols after a DEACTIVATE until the end or encounters another ACTIVATE symbol. Like this:
[
# ...
AdaptiveMaxPool1DSymbol(out_features=3369),
LinearSymbol(bias=False, out_features=3595),
# all the symbols below will be deacitvated
SimpleSymbol(type=SymbolType.DEACTIVATE),
AdaptiveMaxPool1DSymbol(out_features=1211), # ignored
AdaptiveMaxPool1DSymbol(out_features=4000), # ignored
SimpleSymbol(type=SymbolType.TANH), # ignored
# all the symbols below will be activated once again
SimpleSymbol(type=SymbolType.ACTIVATE),
AdaptiveMaxPool1DSymbol(out_features=3506),
LinearSymbol(bias=False, out_features=3256),
# ...
]
Before the symbol sequence goes into the building process, a pre-processor will remove all the symbols between DEACTIVATE and ACTIVATE pairs.
From a biological perspective, atavism is based on the fact that some gene sequences are in the DNA but deactivated because they are not needed in the current environment.
REPEAT_START / REPEAT_END
The symbols REPEAT_START and REPEAT_END pair make repeating a sequence of symbols possible.
The REPEAT_START takes a times argument to determine how many times to repeat.
The repeating section can also be nested.
Here’s an example:
[
# ...
# all the symbols below will be repeated twice
RepeatStartSymbol(times=2),
LinearSymbol(bias=False, out_features=3256),
SimpleSymbol(type=SymbolType.RELU),
# all the symbols below will be repeated three times
RepeatStartSymbol(times=3),
AdaptiveMaxPool1DSymbol(out_features=1211),
SimpleSymbol(type=SymbolType.REPEAT_END),
# without REPEAT_END, it will repeat everything till the end
# SimpleSymbol(type=SymbolType.REPEAT_END),
# ...
]
Of course, to make it fault-tolerant, we ignore the REPEAT_END before the REPEAT_START symbol.
And it’s okay if there’s no corresponding REPEAT_END.
It will just repeat symbols until the end.
BRANCH_START / BRANCH_SEGMENT_MARKER / BRANCH_STOP
A neuron network may not always be a straight linear structure.
There could be branches.
A well-known approach to help make backpropagation much easier is to adopt a residual neural network structure.
The BRANCH_START, BRANCH_SEGMENT_MARKER, and BRANCH_STOP symbols made having an arbitrary complex branching structure possible.
It works like this: the start and end symbols mark the sequence of symbols, and the BRANCH_SEGMENT_MARKER cuts the sequence into segments.
They can be nested as well.
Here’s an example
[
# ...
# mark the beginning of branching structure
SimpleSymbol(type=SymbolType.BRANCH_START),
# first segment
LinearSymbol(bias=False, out_features=3256),
SimpleSymbol(type=SymbolType.RELU),
# the symbol BRANCH_SEGMENT_MARKER marks end of the first segment
SimpleSymbol(type=SymbolType.BRANCH_SEGMENT_MARKER),
# second segment
SimpleSymbol(type=SymbolType.TANH),
# branch can be nested as well
SimpleSymbol(type=SymbolType.BRANCH_START),
# ... content of nested branch goes here
SimpleSymbol(type=SymbolType.BRANCH_STOP),
# marks the end of branching structure
SimpleSymbol(type=SymbolType.BRANCH_STOP),
# ...
]
And, of course, I made it fault-tolerant.
We simply ignore invalid branching symbols.
Regarding BRANCH_STOP, we join all the branch segments back into just one.
Currently, we simply use cat to concrete all the tensors from all branches.
In the future, I will take a random parameter to determine whether to concat/stack/add or even more joint operations.
RELU / LEAKY_RELU / TANH / SOFTMAX
The Relu, LeakyRelu, Tanh, and Softmax are common functions applied in a neuron with PyTorch.
Therefore, I made each of them a symbol so that we can add them to the network.
The most interesting part is LeakyRelu. It comes with a negative_slope parameter default value set to 0.01.
I am considering making it an adjustable parameter because I think adding randomness might be helpful in a large neuron network based on my experience building large-scale distributed systems.
LINEAR
The LINEAR symbol is used to build a Linear module.
It takes out_feature and whether to have a bias or not parameters.
We automatically add a Flatten module before the linear provides if the previous output tensor shape is not 1D.
When creating one, it also automatically takes the previous output tensor size as the in_features parameter.
ADAPTIVE_MAXPOOL1D / ADAPTIVE_AVGPOOL1D
The ADAPTIVE_MAXPOOL1D and ADAPTIVE_AVGPOOL1D symbols are used to create AdaptiveMaxPool1D and AdaptiveAvgPool1D.
They both take one out_features parameter.
Yet another challenge: PyTorch module tensor shape mismatch problem
So, as you can see, I didn’t support too many operations. Most convolutional are not included yet. If you are already familiar with machine learning, you probably already know that it’s actually challenging to handle different sizes/shapes of input and output of each module. There are many ways to do it: you can pad it, expand the input size, and take a view of whether the output size is bigger than the input size or max pool it. Not to mention, there are also various dimensions.
A silly way to move forward is to simply flatten everything into a single dimension, but then you will lose valuable positional information. There could be infinite combinations of output and input size to match if we don’t limit the dimension. I am considering limiting the dimension to three to avoid the problem. In most cases, I imagine trying to snap the previous output and input neurons together in a physical world.

A diagram shows that input and output neurons are in 2D dimensions but of different sizes. We try to overlap as many neurons as possible.
Maybe a rule of thumb is to have a deterministic algorithm to maximize the overlapping of neurons. If there’s value not captured downstream, it’s just a waste of a bit of computing resources, not the end of the world. The network should work regardless. I haven’t addressed the problem yet. That’s why it only supports 1D operations for now.
Gene’s binary encoding with Huffman tree
Okay, now we have a simple symbol system and a way to connect the generated modules. With that, we can easily create random models with a sequence of those symbols. This, for example:
[
RepeatStartSymbol(times=2),
SimpleSymbol(type=SymbolType.BRANCH_START),
SimpleSymbol(type=SymbolType.LEAKY_RELU),
SimpleSymbol(type=SymbolType.TANH),
LinearSymbol(bias=False, out_features=2738),
SimpleSymbol(type=SymbolType.DEACTIVATE),
SimpleSymbol(type=SymbolType.BRANCH_STOP),
SimpleSymbol(type=SymbolType.LEAKY_RELU),
RepeatStartSymbol(times=3),
SimpleSymbol(type=SymbolType.ACTIVATE),
AdaptiveMaxPool1DSymbol(out_features=1874),
LinearSymbol(bias=False, out_features=872)
]
And its corresponding PyTorch model is like this:
Sequential(
(0): LeakyReLU(negative_slope=0.01)
(1): Tanh()
(2): Flatten(start_dim=1, end_dim=-1)
(3): Linear(in_features=784, out_features=2738, bias=False)
(4): Reshape()
(5): AdaptiveMaxPool1d(output_size=1874)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1874, out_features=872, bias=False)
(8): LeakyReLU(negative_slope=0.01)
(9): Tanh()
(10): Linear(in_features=872, out_features=2738, bias=False)
(11): Reshape()
(12): AdaptiveMaxPool1d(output_size=1874)
(13): Flatten(start_dim=1, end_dim=-1)
(14): Linear(in_features=1874, out_features=872, bias=False)
)
Next, how should we encode the symbols? I would like to have an encoded representation of those symbols to make it much easier to merge two genes, generate offspring, and provide mutation. A binary string seems like an easy way to merge, store, and share. I envisioned we could have bits from two agents side by side and randomly pick from one of them to generate the offspring.

We can randomly choose each bit from both parents by representing genes as binary numbers.
In that way, if both parent agents have the same gene in most cases, those would remain the same. If not, it would be randomly inherited from one of its parents. Mutations such as cutting and duplicating are also easy. Just operate on the bits.
I thought about how the encoding should work. There are many different building blocks in the neuron networks. Are they all created equal? Maybe there should be some preference? Maybe some symbols should appear more often; some should appear less. With that in mind, I come up with the idea of using Huffman encoding. Originally, this was for data compressing. But I thought, maybe in the random bits, some more frequently appearing bits combination should represent more frequent symbols. And I don’t want to decide which one should be used more often; it’s up to the agent’s gene to decide.
With that in mind, I let each agent generate a symbol table, mapping symbols to a random frequency. I then constructed a Huffman tree based on this symbol table. Then, I can consume any random bit stream into a stream of symbols with the Huffman tree. For example, with a symbol table like this:
{
"BRANCH_START": 765,
"BRANCH_SEGMENT_MARKER": 419,
"BRANCH_STOP": 52,
"REPEAT_START": 384,
"REPEAT_END": 455,
"ACTIVATE": 797,
"DEACTIVATE": 939,
"RELU": 965,
"LEAKY_RELU": 293,
"TANH": 179,
"SOFTMAX": 209,
"LINEAR": 343,
"ADAPTIVE_MAXPOOL1D": 397,
"ADAPTIVE_AVGPOOL1D": 483,
}
The random bytes b'g\x14\xb4\x1c\x04' will be a symbol stream like this:
[
SimpleSymbol(type='RELU'),
SimpleSymbol(type='BRANCH_START'),
SimpleSymbol(type='BRANCH_SEGMENT_MARKER'),
SimpleSymbol(type='REPEAT_END'),
SimpleSymbol(type='LEAKY_RELU'),
SimpleSymbol(type='ADAPTIVE_AVGPOOL1D'),
SimpleSymbol(type='REPEAT_START'),
SimpleSymbol(type='RELU'),
SimpleSymbol(type='LEAKY_RELU'),
SimpleSymbol(type='REPEAT_START')
]
Pretty cool, huh? Well, while it’s convenient and efficient to have a gene sequence present in binary format. However, in terms of merging two gene sequences and mutation, any bit change will greatly affect downstream since the encoding was originally designed to compress data by removing redundancy. Therefore, I am still thinking about a way of better representing them in binary to overcome the drawbacks. Or, you know what? Maybe I can operate the gene sequence as symbols directly. Regardless, I will leave that topic for my next iteration and yet another article to cover this portion.
Agents should pay for their computing resource
When I look at many machine learning approaches, I realize one problem is the immediate reward system. In the real world, some may spend a long time playing the long-term game and finally win big. The immediate reward system makes it hard for a network to play the long-term winning game.
Also, a random network can grow as big as it wants without limitations. Usually, a bigger network performs better, but a smart network might outperform a bigger one. Therefore, I designed the system to give each agent limited credit. Each time we run the agent in the environments, we subtract its operation costs from its credit. If they get the right prediction or behavior, they get a reward based on its accuracy. If the agent runs out of credit, it’s marked as dead and won’t be able to produce offspring. Hopefully, we can have efficient networks by having a series of environments forcing them to be so.
Yet another reason I adopt a credit system is to enable agents to work together. In the end, we only care about the right answer or behavior from the end-user’s perspective. We don’t usually care what happens in between. However, if an agent can only be rewarded as they output data directly to the final output data sink, only that agent can get credits. I want to allow an agent to flow its credit to another agent in exchange for input values. In that way, we can design a series of environments to force different agents to specialize and become more efficient as a whole.

Diagram shows different agents connects together in between of input and output layer
The final purpose of the currency system is to make it a competitive environment for agents. We can either control the supply of currency or limit slots for reproducing to force them to compete with each other. But in some situations, we may want them to work together, i.e., Nash equilibrium. The current idea is to have limited reproducing slots in each zone after all agents go through their epochs and see how much credit they have left to decide how many offspring they can produce.
Why the random agent works well
One benefit of evolving random neurons works is that we can pick up the high performers, look at their structure, and try to find out why it works better than others. We could learn some new tricks and patterns from them. We may find a new pattern like CNN, a transformer, or something similar, but we will train 100 times faster.
Take the example at the beginning of this article; I wonder why, despite that, it looks like nonsense at a glance, and yet it performs decently. I tried MNIST/QMNIST/FasionMNIST, and it all works great on those datasets. I know MNIST is just the hello world level of the dataset for machine learning, but I think it’s remarkable that a randomly generated network performs well on them.
I looked at the model and found something interesting. It has AdaptiveMaxPool with an output size bigger than its input size. The input size from MNIST is 28 * 28, i.e. 784. Wait, what? All the tutorials or examples on the internet only show you that you can use the max pool to aggregate data into smaller sample sizes. What the hell is going on with a maxpool output more than its input? I wrote a simple script to try out and realized it works like this:
a = torch.tensor([[1.0, 2.0, 3.0, 4.0]])
m = nn.AdaptiveMaxPool1d(13)
m(a)
# output: tensor([[1., 1., 1., 2., 2., 2., 3., 3., 3., 4., 4., 4., 4.]])
For PyTorch, when a max pool output size is bigger than the input, the input values will be upscaled into the output by duplicating the input values. I don’t fully understand the mathematical implications of backpropagation and why it trains faster with duplicate signals. But my educated guess is that duplicating the same signal provides more paths down the gradient at low cost.
To show that the upscaling works well, I added handcrafted models with two simple linear layers, another model with max pool upscaling, and the randomly generated one. Here’s the plot:
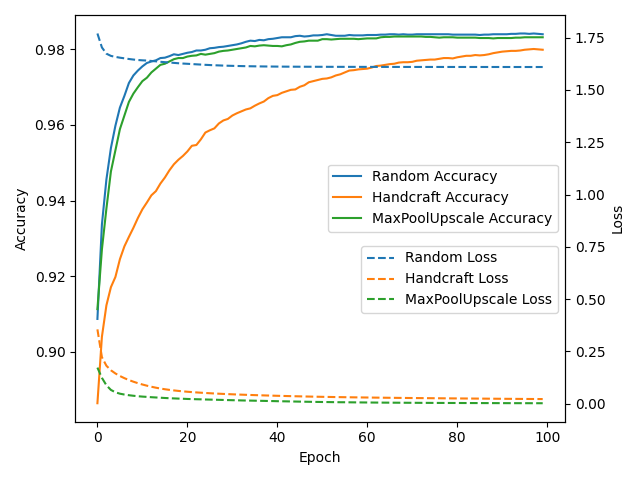
Plot of the random generated model, handcraft one and the max pool upscaling one.
Interestingly, the random one always has a high loss of around 1.5, but it performs the best. I don’t know where the loss is coming from. The second goes to the upscale one. The final one would be the handcraft of two linear layers. Please note that I don’t have much time for this rabbit hole, so I casually pick numbers.
The source code and what you can do with it right now
I have open-sourced the MAZE project here under an MIT license. I am still working on the environment part, but there’s already a workable system to produce neuron networks based on the given stream of symbols. For example, like this:
from torch import nn
from .environment.agentdata import AgentData
from .environment.vehicle import Vehicle
from .gene.symbols import LinearSymbol
from .gene.symbols import RepeatStartSymbol
from .gene.symbols import SimpleSymbol
from .gene.symbols import SymbolType
vehicle = Vehicle(
agent=AgentData(
symbols=[
RepeatStartSymbol(times=2),
LinearSymbol(bias=True, out_features=1960),
SimpleSymbol(type=SymbolType.RELU),
],
input_shape=(28, 28),
),
loss_fn=nn.CrossEntropyLoss(),
)
vehicle.build_models()
# do whatever you want with the PyTorch model `vehicle.torch_model`
You can then run the model against datasets easily with PyTorch like this:
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
training_data = datasets.MNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
# Download test data from open datasets.
test_data = datasets.MNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
batch_size = 64
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
for epoch in eval_agent(
vehicle=vehicle,
train_dataloader=train_dataloader,
test_dataloader=test_dataloader,
):
print(epoch)
Please expect rapid changes to this repository as I am working on it. And bugs, of course. However, you can also look at previous commits to try out the above examples. I will leave them in the article00 tag.
The next step
The next step I would be focusing on is getting agents to produce offspring with mutations and run them on a large scale. I didn’t cover all the details of how I would do them because otherwise, it would make this article too long. Some details may still need to be ironed out, and maybe prototyping a little bit. We will talk about them in a later article in this series. I will probably build a simple web UI that allows users to view all the agents and environments. I might just upload all the data so that you can also look at them and find interesting model structures from them. It’s too bad that I don’t have 6 million USD to burn for this pet project. But maybe I can find a smart way to do it. 😅
There are many interesting questions I have in mind when building this. I may not be able to answer all of them down the road, but it’s helpful to write them down upfront as a reminder to myself as well. Here they are:
- Is backpropagation the right way to do it? Or we could let the agent develop a network to tune their weight and biases.
- What about baking the parameters into the gene? Can we have an offspring agent perform well immediately without or with little training?
- What about parenting? An agent generates data for its offspring to help the training or turn their weight and bias directly.
- How big is the scale we need to run this experiment?
- How do we enable agents to work together? Should we let them have extra input and output to communicate with each other?
- Given a large known working model such as an LLM, can we use MAZE to find an equivalent network that outperforms the original (like using fewer computing resources)?
- Would randomly generated networks with random layer size and feature count outperform human-crafted ones? We, humans, tend to use “beautiful numbers.” Is there anything randomness can help, like in a distributed system for neuron networks as well?
- The original idea of the environment is to have agents of a certain degree to explore freely instead of relying on training data. Maybe I need to build some simulators.
That’s it for now. I hope you find my little pet project somewhat interesting. And stay tuned for my next article. We will soon find out how random neuron networks and their offspring perform in the MAZE!