This is the second article in the MAZE machine learning series. To learn more about what is MAZE (Massive Argumented Zonal Environments), you can read other articles here:
More than one week has passed since I published my previous MAZE article. I spent most of my spare time besides my work on this project, and I have already made significant progress. I can’t believe what I’ve done in the past week with just myself. I am very proud to have achieved this much in such a short time. Today, I want to share the latest update about the MAZE project.
MAZE Web app
First, as promised in the previous article, I wanted to build a UI that made researching much easier and publish the data publicly so that anybody interested in machine learning could view those neuron networks. People can learn a new trick or two or even open new research based on the latest effective patterns found through MAZE. And yes, I deliver! Here are some screenshots from the web app:

Screenshot of MAZE web app experiment page
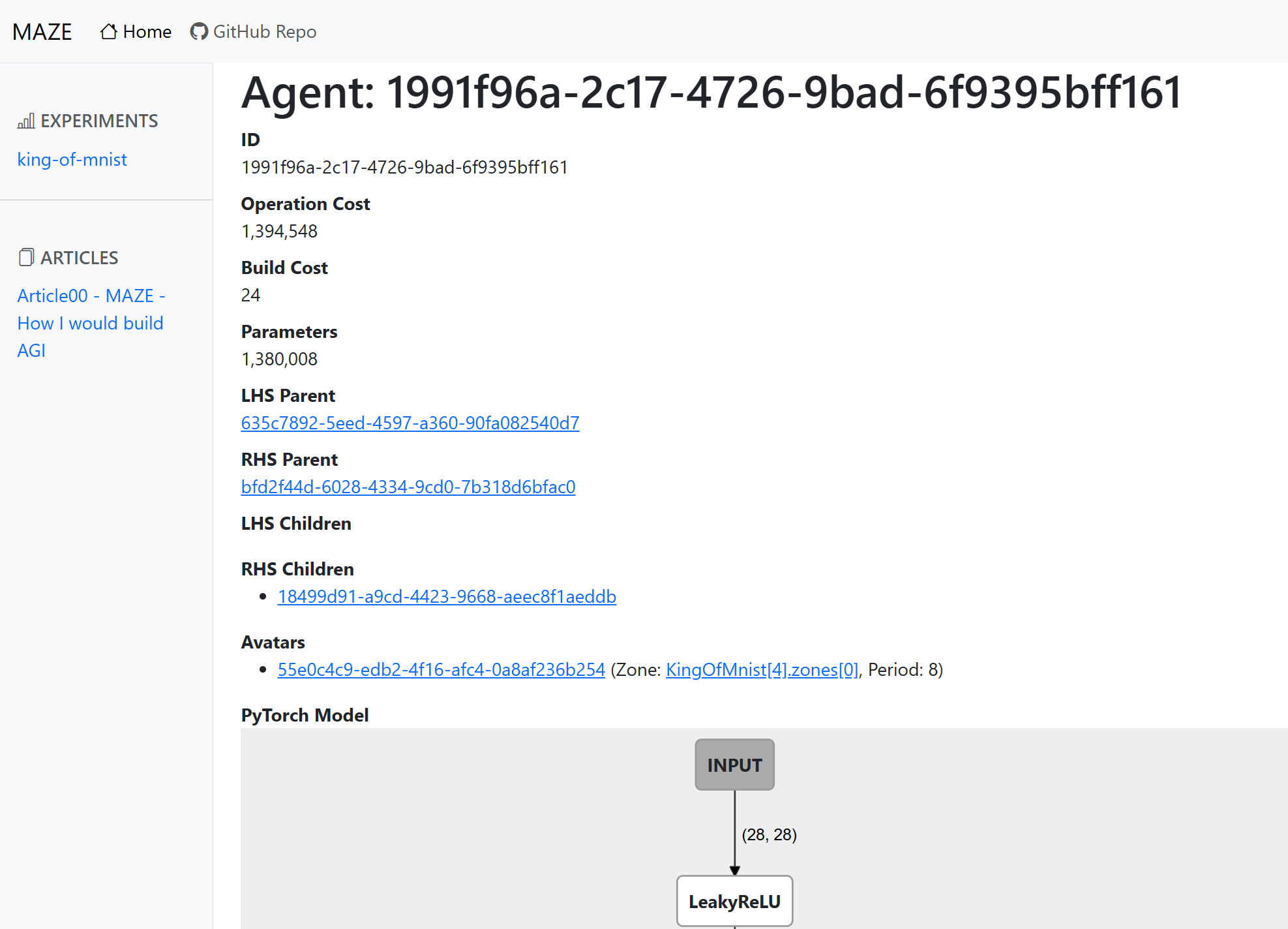
Screenshot of MAZE web app agent page
I published the web app at here, and you can visit yourself to find out:
As you can see, the domain name has article01 as a prefix because I will move at light speed in improving it by making lots of changes, and I don’t want to maintain backward compatibility.
So, this website will be a snapshot of my initial test rounds.
During the development of MAZE, I realized it’s tough to learn how a model works by reading its gene code, so I made it possible to view each model’s PyTorch module DAG (Directed acyclic graph) directly. Here are some really interesting examples, like this complex one with many branches:
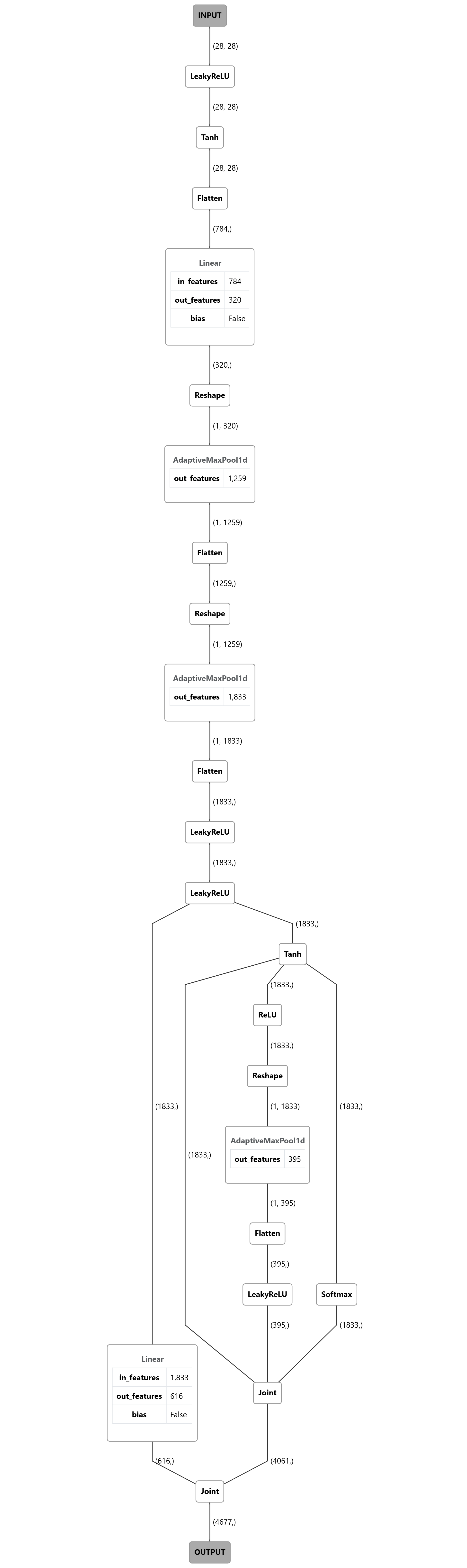
DAG diagram of a neuron network with linear and maxpool at the beginning then connect to many branches at the bottom with a few modules before the output node
I will show you more interesting examples in the following sections.
Generating offsprings
One critical piece missing from the previous article was how we can generate offspring for agents. The original idea was to design a binary encoding system to encode the neuron network structure and directly merge the bits. The first attempt was to use Huffman coding. It doesn’t work well because the encoding is too sensitive to any tiny change and is highly context-sensitive. DNA doesn’t work like that; it’s way more fault-tolerant.
Interestingly, I just watched a video about how the Google Deepmind team solves protein folding problems using machine learning. The video shows one particular example. A sequence of Amino acids is slightly different in different animals, but they mostly look the same.

Screenshot from the video The Most Useful Thing AI Has Ever Done showing different animals' Amino acids have the same prefix but different suffix in terms of composition
There are some changes in the sequence, but they fold similarly regardless of the slight differences in the compositions. Therefore, the protein functions similarly. The magic of life is tiny variants like these accumulate over time. While they may seem useless most of the time, a key mutation happens, and it could change the way it works differently and thus provide a potentially new solution for life to survive.
It is possible to design a fault-tolerant binary encoding for this project. Many fault-tolerant encoding approaches exist for data transmission or storage in computer science. But it doesn’t provide much value than just making it require more bit flips to change the meaning of a symbol. If the binary form encoding itself doesn’t provide any more value than being fault-tolerant, it doesn’t make too much sense.
With that in mind, I’ve decided to operate on the gene symbols for neuron network construction directly before I develop any good idea. My approach is straightforward: merge two symbol sequences, line up two side by side, and then randomly choose from either one of the parents.

Diagram shows that we choose randomly from either LHS (left-hand-side) parent or RHS (right-hand-side) parent and merge the parameters random if the symbol type is the same on the both side
If they are different symbols, we will pick one randomly. But if they are the same type of symbol, we will merge parameters. We pick a random value between the two parents for each parameter.

Diagram showing that we pick the value of parameter randomly between the LHS (left-hand-side) parent and RHS (right-hand-side) parent
With this approach, agents should eventually be able to reach the final optimal parameter value after many generations. But here comes a problem: since we only pick the number within the parents’ range, the parameter value can never go outside its ancestors.

Diagram shows that parameter value moves closer and closer to an ideal target value after many generations
An interesting question: where do those initial parameter values come from when we create the first-generation random agents?
Well, we choose those initial parameter values from an initial constant range.
When I built this system, I hated picking a “reasonable” number range for a parameter.
For example, the range of the Linear operator’s possible out_features size.
What should be the right size for this parameter?
100? 1,000? 4,096? 8,192?
The problem is that by imposing the parameter boundary, we reduce the space of what an agent can explore.
What if the optimal parameter value is outside the initial boundary I picked?
I don’t know what the correct values are, and I shouldn’t know.
It’s up to agents and the design of environments in the MAZE to guide it to the optimal values.
So, ideally, we should let agents go crazy with whatever parameters they want to use. As mentioned in the previous article, we have already implemented a credit system to take the operation cost into consideration, so there’s no need to worry about the boundless parameter to make an agent eat all the computing resources. However, we still need to pick something small enough. Otherwise, we would search for the right parameter in an unbound space initially, which may take forever. But we still want to make it possible for those values to grow outside of our initial constant random range. To overcome the problem, we start with our initial random range and then allow the offspring’s parameter value to exceed the parents in a small window of jittering.

Diagram showing that we pick the value of parameter randomly between the LHS (left-hand-side) parent and RHS (right-hand-side) parent plus a jittering window to allow the value grow outside of parent's range a little bit
Okay, now you may ask what the right size of the random jittering window for each parameter type is. Well, I also hate to answer that question, but that’s another rabbit hole I don’t want to go into right now. In the current MAZE implementation, I pick a few values that make sense to me. The worst case is that the jitter is too tiny and takes more generations to hit the right target. But it will eventually hit the target with a large enough scale and time.
Period and epoch. Breeding and promotion.
With the above breeding approach, we can combine two agents and produce offspring. But here comes another question: When is the right time to do it? And what does “time” even mean to an agent, anyway? We need to evaluate an agent to know if it’s good or bad before we make any decisions. Therefore, one obvious choice is to assess all agents and decide which to breed and promote in the following environment.
An interesting term, epoch, is used in training an AI model. When you finish a cycle of feeding training data to a model, applying backpropagation, and then running a test against the model, we call that cycle an epoch. I looked it up quickly, and the term epoch comes from geology. In geology, the unit includes epoch is the period. Therefore, I picked the period as the unit representing a cycle of evaluating all the agents in the environments. At the end of the period, we need to do two things: breeding and promotion.
For now, we design zones to have limited agent slots, which, in one way, makes it much easier to run in a distributed computing environment by assigning a zone to a dedicated machine or a cluster in a local network. On the other hand, we want to let the zone have limited slots so that the agents can compete for reproduction and promotion. Now, let’s see how breeding and promotion work.
Breeding
First, breeding happens only between agents inside a zone. This allows us to control what we breed in the zone since we control what agents enter it. The process is straightforward: We rank all the dead agents in the latest period by their accumulated credits and pick randomly based on probability proportionally to their total credits in the zone. In other words, the wealthier they are, the more likely they are to have offspring (yeah, super not politically correct, I know 🤣).

Diagram shows that we randomly pick best performing pair of agents in the zone and generate offspring from them and put them into the same zone for the next period
A good agent is a dead agent; this is true in MAZE because a dead status means it finishes all the epochs without running out of credit or into other errors. And yes, unfortunately, death is a feature rather than a bug for life. We may talk about that later.

The Death and dog meme originally by Seebangnow, modified by me. The Death told a neuron network it's time to go. Neuron network asks the Death, was I a good neuron network? The Death replied: I was told you’re the best. You train quickly, use little resource and has no vanishing gradient problem
Those offspring go back into the zone for the next period. How many offspring should we create in a zone, one may ask? Each zone has a limited number of agent slots, and we can let all offspring take over, but there is no room for the promoted agents from the other environments. A better way is to set a percentage for local offspring and remaining slots for immigrants.
Promotion
We must perform breeding first because sometimes a zone may not have enough qualified agents to produce offspring. Therefore, there will be empty slots. We run promotions after breeding to claim all the remaining slots.
This process is also straightforward as well. In my current test run environments, I rank agents from all zones of all environments in the current period. I calculate the opening slots in the next environment and then select the top ones.

Diagram shows that after breeding is done, we select the best agents from the previous environment in the current period and put them into the free slots in the next period for all zones
King of MNIST
To develop the whole MAZE system, I’ve decided to build the first MAZE experiment with the MNIST dataset. Once again, MNIST might not be the most sexy dataset in the world, but it’s a good foundation for testing a novel machine learning theory and framework. I named it “The King of MNIST.” The idea is to find a cost-efficient MNIST classifier with as high accuracy as possible.
The design of the environments is simple. It’s a linear series of environments connected from one to another. The next one has fewer zones. We also make earning rewards more challenging. Few zones with the same number of slots make competition higher. Making it harder to earn income selects agents with better and better accuracy. Here’s the reward formula:
\[reward = reward\_amount * accuracy^{reward\_difficulity}\]We increase the reward_difficulity from 5 to 9 in those five environments.
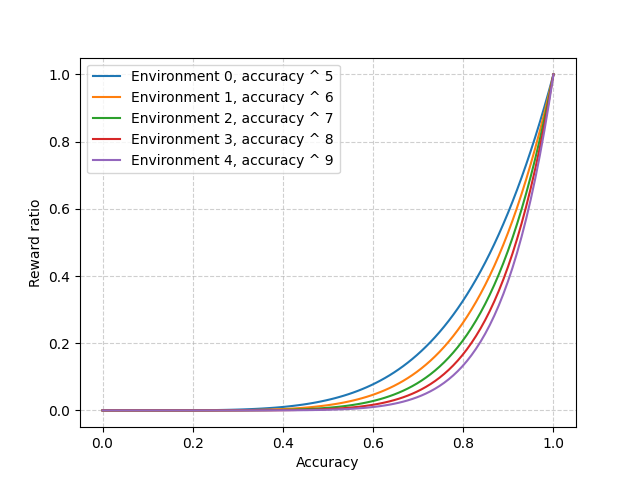
Plot shows the curve of different reward_difficulity as the exponent value for accuracy, the higher the reward_difficulity, the harder to earn reward
A higher exponent value means that a slightly higher accuracy could gain more income and thus have better advantages in making more offspring. The early-stage environments also run fewer epochs as many agents are predominantly random, and we don’t want to waste too many computing resources. With all these, here’s what the experiment looks like:

The diagram shows environments connected together one-by-one, from more zone to less zones, from easy to hard, from little epoches to many epoches
I don’t have many spare computing resources, and this is still under development, so it’s just a very small-scale test run. At the time of publishing this article, it had just passed the 14th period. I might let it run a little bit longer, but after I add some improvements, I will start a whole new experiment. Still, despite the small scale and short periods, I have already seen some interesting neuron networks that accumlates great credit along the way. Like this one comes with 98.34% accuracy.
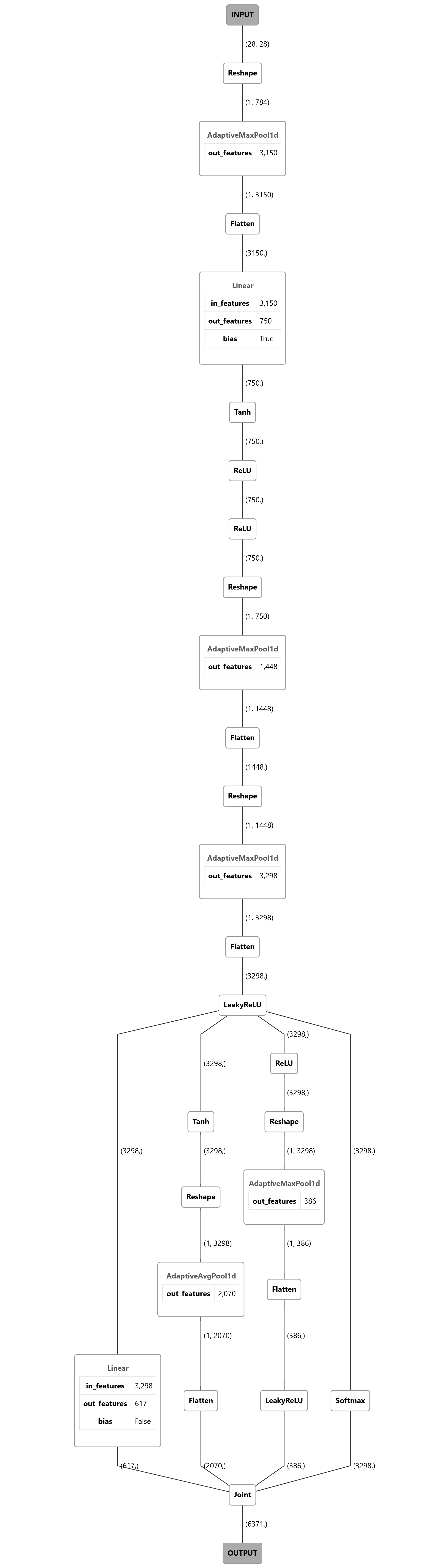
A neuron network model with linear and max pool at the beginning and then branch out to linear, avg pool, max pool and softmax
While this looks cool on paper, unfortunately, I tested them with my own number handwriting. If the number of positions goes off-center or the stroke width is not close enough to the MNIST dataset, it usually makes a wrong prediction. A model like this probably gets higher accuracy based on memorizing pixel positions instead of finding a smarter way to recognize them, like CNN networks with different filter kernels. Of course, we haven’t added CNN (Convolutional neural network) operations, so the agents cannot use it yet. If we want, I can build a new data pipeline to twist the existing MNIST dataset with slightly random transformations, like rotation, and translation, to make it more fault-tolerant. But that’s not my current focus today.
You can read the source code here if you’re interested in how I implemented King of Mnist. Of course, the API is subject to change.
Run it on a large scale
I am currently putting all the data in a PostgreSQL database to run MAZE on a large scale. Thanks to PostgreSQL’s SKIP LOCKED feature, we can do this efficiently by selecting only the rows that are not locked yet. This approach allows us to have a simple yet robust way to scale. Of course, we will be limited by the connection count of a single PostgreSQL instance, but that’s already a significant number. I don’t anticipate to hit the limit anytime soon.
After I made it possible to run concurrently, I tried to run it on different machines.
One platform I’ve tried is Apple Silicon, an Apple M1 Mini.
PyTorch comes with MPS (Metal Performance Shaders) support, but unfortunately, it doesn’t support operations like max pool with out_features that’s not a factor of its in_features.
I don’t plan to jump into that rabbit hole yet, so for now, I can only run the experiment on CUDA with my PC, which has an NVIDIA GeForce RTX 4090.
The joy of getting your curiosity fulfilled
So far, I have had a lot of fun working on this pet project. Since I started running MAZE for its first experiment, every day has been like Christmas. Every day, I wake up and rush to my computer, opening the browser to see what the interesting new neuron network has evolved in the MAZE. And I can’t help but think about all the other interesting approaches I can try on this framework. It’s hard to describe the joy of getting your curiosity fulfilled.
I talked to people in the industry about my idea for this little pet project: evolving machine-learning models based on gene merging and mutations. They mentioned that it reminds them of the early days of OpenAI research. I didn’t follow OpenAI’s work closely, but I recall seeing they had some very interesting stuff in the past, such as making agents play hide-and-seek. That indeed looks like a very interesting project. Surely, LLM is very cool, but I just hope there’s more diversity in machine learning research instead of LLM. I want to write it down to remind myself of the joy of doing research like this, to stay curious, to stay open-minded, and to never stop learning.
Next step
Now, we already have a MAZE system that allows you to run AI model evolution on a large scale. You may notice something critical missing: mutation. Yes! I have already finished the design and implemented part of the code, but I haven’t found time to integrate it yet. So please keep in mind that the experiments you saw above are all running without any mutation. The next step will be incorporating mutation so agents can evolve more freely.
Currently, the Joint operator only supports concatenating, other than mutation. I will support addition and other operations. I may also add another type of operation to give the agent more freedom in its evolution. And, of course, I will improve the web UI to provide more visualization, such as adding an ancestors tree.
Even though this is just a pet project right now, I think it already shows some potential. While LLM is very powerful, it’s not for all situations, and reducing model size and operation cost is still very hard. I believe the need for running models will increase with low-power consumption devices. The need for different types of efficient models other than language processing will also explode. One of MAZE’s superpowers is finding the optimal cost-efficient network to deploy on devices. It would be very expensive and hard for companies to hire AI researchers to design and fine-tune those models.
With enough freedom, I think MAZE can conquer any challenges thrown at it as long as the provided data or simulated environment and MAZE design are decent (of course, these are very hard by themselves). I hope MAZE can make it much easier to adopt machine learning. While the project is open-source, it doesn’t provide many documents besides my articles. I will also write some documents to introduce you to running MAZE locally and designing your own MAZE to breed the desired neuron network. I may also add another type of operation to give the agent more freedom in its evolution.
That’s it for today’s update. Thank you so much for reading. Stay tuned for my next article. If you find this article interesting, please help me share it around!