Have you ever wondered why machines need a dedicated training process while humans can learn from experience? I wondered the same thing for a long time. Today, I’d like to introduce continual learning with the Marketplace algorithm, which demonstrates the possibility of machines learning new things by simply doing!
This is the third article in the Marketplace algorithm series. Please read the first article and second article for details on the Marketplace algorithm. Last week, I published the second article, which discusses using all the probes to compose the best parameter delta. It was a lot of fun! 😄
However, training a model like a normal training process is not the most exciting application of the Marketplace algorithm. The previous articles were just appetizers; the main course is here. The most intriguing application of the Marketplace algorithm is continual learning. I had this idea almost immediately after developing the Marketplace algorithm. After running through the concept in my mind, I believed it was feasible. So, I spent a few days implementing it, and it worked! It still has a long way to go, but it already shows great potential.
The experiment’s design is straightforward. First, I trained the beautiful MNIST model from Tinygrad using the Marketplace V2 algorithm and the digits dataset for 2,000 steps, achieving 96% accuracy on the validation dataset. Next, I took the trained model, simulated the inference process, and added class 3 (dress) from the Fashion MNIST dataset, mixing these images with the digits dataset to allow the model to classify them.
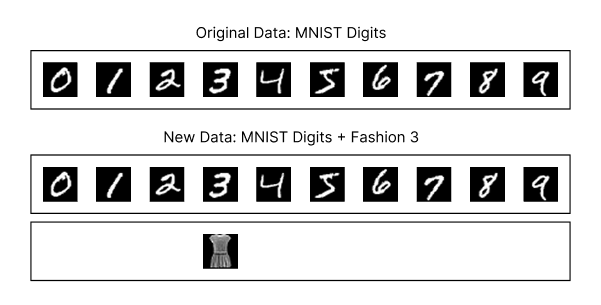
A diagram showing the original MNIST digits dataset and the new dataset, which combines the MNIST digits dataset with class 3 (dress) from the Fashion MNIST dataset.
I applied the Marketplace algorithm to enable the model to continually learn the new dress images gradually with each step. The goal was to determine whether the model could learn the new dress images primarily through inference, without dedicated training, while still classifying digits correctly most of the time to provide business value. Here’s the result:
As shown, the model gradually learns the new dress images over several steps while maintaining its ability to classify digits correctly most of the time. These steps involve only inference, with no dedicated training process!
The implications of this technology are tremendous. I believe the future of machine learning lies in learning rather than training. Companies that master this approach in production will gain a significant advantage because their models improve as more people use them, quickly and without much additional cost. As the model improves, it attracts more users, creating a flywheel effect: the more it’s used, the better it becomes. Best of all, this approach requires almost no additional computational cost for training. Of course, this is just a proof of concept, and there are still many improvements to make and challenges to overcome. Nevertheless, I’m thrilled about the possibilities of continual learning. Today, I’m excited to share my first take on continual learning with the Marketplace algorithm.
Context for New Readers
This article continues my journey to tackle the challenge of eliminating backpropagation using first principles. As this series of articles is now reaching a wider audience, some new readers may have missed the context of this article, so I’d like to provide it here. I aim to explore how far I can push this idea without referring to academic papers. I haven’t read any papers specifically on this topic. Many people on X have recommended academic papers to me, and I truly appreciate their suggestions. Unfortunately, I don’t have time to read all the papers thoroughly. If I had to read every paper before starting my research, I’d see you again in five years! 😂
For this reason, my definition of continual learning may differ from others’. Here’s my definition of continual learning: It means that a model can learn new concepts primarily through inference alone. The model should adapt to new data gradually. Others may have explored similar ideas, but I’m unaware of their work. As this is independent research, please take it with a grain of salt.
How It Works
Previously, when using the marketplace algorithm to train a model, we fed the same batch of data with different permutations of vendor deltas for the model parameters. We calculated the loss of the final output and attributed it to the parameter delta that contributed to it, then composed the reconciled delta as the direction to update the model parameters. Consequently, the same data passed through the model via all possible paths.
For inference, this approach is impractical due to high computational costs. The advantage of enabling the model to learn new information through inference is that it operates at a way larger scale. We can process a large volume of input data through the model across various paths. With that in mind, instead of passing data through all possible paths, we select just one random path for each inference.

A diagram showing the inference process using a single random forward pass instead of all possible paths.
After passing data through the model, we retain the chosen random path. If the label is known, we keep the loss; otherwise, we store the logits and input data for later labeling.
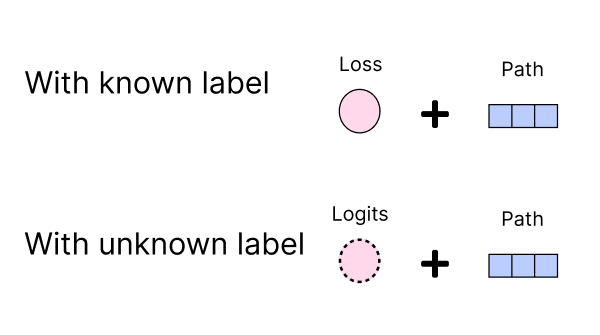
A diagram showing that we retain the chosen random path and either the logits or loss, depending on whether the input data label is known.
After collecting a sufficient number of paths along with their logits or loss, we can generate the reconciled delta, as described in the V2 article. Before doing so, we may want to filter out unrepresentative data. In this step, we can select which final outputs (you may need to keep at least some metadata to tell which to keep or not) participate in the reconciliation process, giving us greater control over the direction of the reconciled delta. For example, we can exclude extreme outliers that are not representative of the data. While we did not apply this filtering in our experiment, but I think it makes sense to do it in the production environment.

A diagram showing the filtering of collected paths and logits or loss based on specific criteria to ensure data quality.
If the collected data is unlabeled, we must label it first and then compute the loss from the stored logits.

A diagram showing the labeling process for input data when the label is unknown.
Using the collected paths and loss, we can then generate the attribution for each loss.

A diagram showing the calculation of attribution for each parameter delta by standardizing the loss using collected paths and loss.
And then likewise, we can generate the reconciled delta by multiplying the attribution from the loss by the contributing parameter delta and summing them.

A diagram showing the process of multiplying the attribution from the loss by the contributing parameter delta and summing them to generate the reconciled delta.
And then, we update the model parameters with the reconciled delta. That’s it! We just process a step in continual learning, performed entirely through inference. This step is analogous to a minibatch in the training process. The model continues to provide business value during this process, with the only additional cost being the reconciliation step.
The First Experiment: Learning to Classify Dresses
Let’s recap the experiment introduced at the beginning of this article. We trained a model using the Marketplace V2 algorithm on the MNIST digits dataset for 2,000 steps, achieving 96% accuracy on the validation dataset. We then took the trained model and simulated the inference process, incorporating class 3 (dress) from the MNIST fashion dataset. We mixed these dress images with the digits dataset and tasked the model with classifying the combined images. For each step, we used 240 images from the original dataset and 16 images from the new dataset, totaling 256 images. The marketplace shape was 4x4x4, i.e, 64 probes in total.
Diagram showing the original MNIST digits dataset and the new dataset, which combines the MNIST digits dataset with class 3 (dress) from the MNIST fashion dataset.
I must admit, this experiment is far from perfect. It serves as a proof of concept to demonstrate the potential of tuning a model using mostly inference. After all, it’s unusual to present a dress image and expect the model to classify it as the digit 3. In real-world scenarios, data shifts are likely to occur gradually rather than through abrupt changes like this one. Despite its flaws, the experiment shows promising results.
The learning (inference) and validation accuracy for the new data (class 3 from the MNIST fashion dataset) are shown in the following figure:

Diagram with 50% smoothing showing the validation accuracy for class 3 (dress) from the MNIST fashion dataset increasing gradually to 86% at 100,000 steps.

Diagram with 50% smoothing showing the learning (inference) accuracy for class 3 (dress) from the MNIST fashion dataset increasing gradually to 100% at 28,000 steps.
As shown, the model gradually learns the new data. Meanwhile, the testing accuracy for the original digits dataset is as follows:

Diagram with 50% smoothing showing the validation accuracy for the original MNIST digits dataset decreasing gradually from 96.2% to 95.2% after 100,000 steps.

Diagram with 50% smoothing showing the learning (inference) accuracy for the original MNIST digits dataset increasing gradually to 100% at 55,000 steps.
The model successfully learns the new data while maintaining high accuracy on the original digits dataset most of the time. However, the validation accuracy for the original digits dataset drops slightly, which is not ideal. More concerning is the downward trend, which we will discuss later.
The loss decreases gradually for both the new data and the original dataset during the learning process (inference):

Diagram with 50% smoothing showing the loss for the new data decreasing gradually during the learning process (inference).

Diagram with 50% smoothing showing the loss for the original dataset decreasing gradually during the learning process (inference).
The accuracy reaches 100% for both the new data and the original dataset during the learning process (inference). This suggests the model may be memorizing the data rather than generalizing effectively. Given the slight decline in validation accuracy for the original dataset, I wondered whether this was due to the model overfitting or “lazily” memorizing the data. To explore this, I tested whether continual learning could still work if the original dataset was augmented. Thus, I rerun the continual learning process with the original dataset augmented alongside the new data, using the augment function from the Tinygrad library.
Here’s the accuracy for the new data with augmentation:

Diagram with 50% smoothing showing the validation accuracy for the new data increasing gradually, though more slowly than without augmentation, reaching 70% at 100,000 steps.

Diagram with 50% smoothing showing the learning (inference) accuracy for the new data increasing gradually, though more slowly than without augmentation, reaching 100% at around 50,000 steps with slight fluctuations afterward.
Interestingly, the accuracy for the new data with augmentation is lower than without augmentation. This suggests that the model’s learning capacity is being shared between the new data and the augmented original dataset.
For the original dataset, the model initially struggles with augmented data, achieving only around 85% accuracy at the start. However, it quickly recovers and improves steadily:

Diagram with 50% smoothing showing the learning (inference) accuracy for the augmented original dataset increasing gradually to 95% at 100,000 steps.
The validation accuracy for the augmented original dataset drops slightly more than without augmentation, from 96.2% to 94.6% after 100,000 steps, but remains within a reasonable range.

Diagram with 50% smoothing showing the loss for the augmented original dataset decreasing gradually from 96.2% to 94.6% at 100,000 steps.
The loss for the augmented original dataset also decreases gradually, though it starts from a higher point due to augmentation.

Diagram with 50% smoothing showing the loss for the augmented original dataset decreasing gradually from a higher starting point than without augmentation.
The loss for the new data also decreases steadily, but more slowly than without augmentation.

Diagram with 50% smoothing showing the loss for the new dataset decreasing gradually, slightly higher than without augmentation.
Second Experiment with a New Digit
The drop in validation accuracy is concerning. I’ve been considering why this is happening and how to address it. Could it be because the MNIST digit dataset differs significantly from the Fashion-MNIST dataset in style? To explore this, I designed an new experiment where we remove one digit from the original MNIST dataset and train the model to classify the missing digit. Specifically, I trained a model on the MNIST dataset excluding the digit 9.

Diagram showing the MNIST dataset excluding digit 9 and the new dataset including digit 9.
Next, I applied the marketplace algorithm to learn the digit 9 through inference. Here are the results:

Diagram with 50% smoothing showing validation accuracy for digit 9, starting at zero until around 18,000 steps, then gradually increasing to 71% by 100,000 steps.

Diagram with 50% smoothing showing learning (inference) accuracy for digit 9, starting at zero until around 18,000 steps, then gradually increasing to near 100% by 36,000 steps, with fluctuations afterward.
Initially, the validation accuracy for digit 9 remained at zero. I suspected a bug in my code—why else would the accuracy stay at zero? However, I noticed that the loss was decreasing, confirming there was no bug.

Diagram with 50% smoothing showing the loss for digit 9 decreasing gradually.
The issue stemmed from the original model being trained without digit 9, while reserving a label slot for it, fixed at zero and expected to output as such. This created inertia in the model against outputting 9. The decreasing loss indicated learning was occurring, but the model hadn’t yet overcome this inertia. After waiting patiently, the validation accuracy eventually increased.
For the original dataset (digits 0–8), the inference accuracy increased gradually, reaching 100% by 50,000 steps, as expected.

Diagram with 50% smoothing showing learning (inference) accuracy for the original dataset, increasing gradually to 100% by 50,000 steps.
However, the validation accuracy for the original dataset dropped slightly from 96.8% to 95.2%, which was frustrating.

Diagram with 50% smoothing showing validation accuracy for the original dataset, decreasing from 96.8% to 95.2%.
To see if we can eliminate the inertia, I retrained the model without digit 9, this time using the ignore_index feature provided by the cross-entropy function to exclude digit 9 from the loss calculation.
My goal was to create a model neutral to the reserved label slot, enabling faster learning of new digits without inertia.
However, the model still exhibited some inertia against outputting 9, though less than before.
Although I couldn’t fully eliminate the inertia, the fact that the training algorithm can overcome it and successfully learn the new digit 9 is encouraging.
Why Is the Validation Accuracy for the Original Dataset Decreasing?
Now, we know that with the Marketplace algorithm, we learn new data through just inference mostly without a dedicated training process. However, the declining validation accuracy for the original dataset is concerning. The goal of continual learning is to deliver business value while gradually incorporating new data. If the validation accuracy continues to decline, the model may eventually fail to provide business value.
With this in mind, I’ve carefully considered why the validation accuracy for the original dataset is decreasing. After closely examining the chart, I noticed that the validation accuracy remains stable until we begin learning the new digit, number 9, and producing valid outputs. My theory is that when new data is introduced, it generates high loss because the model has not encountered this type of data before.

A diagram showing the loss gap between the new digit, number 9, and the original dataset is huge at the beginning and gradually decreases.
Given the significant loss gap, the Marketplace algorithm prioritizes parameter updates that reduce the loss for the new data, which are often low-hanging fruit. However, the model already has parameters critical for correctly predicting the original dataset. Modifying these critical parameters is costly. In the early stages, the algorithm selects updates that are not critical to the original dataset, focusing on easy wins for the new data. Over time, as the low-hanging fruit diminish, the algorithm begins to adjust parameters that are critical to both the new and original datasets. Since the new data typically has a higher loss, the algorithm prioritizes updates that have a greater positive impact on the new data, even if they negatively affect the original dataset.
If this theory is correct, I predict that a balance between the two datasets will eventually emerge. When the loss for both datasets becomes nearly identical, the algorithm will select parameters that equally impact both datasets, stabilizing the validation accuracy for the original dataset.
In the real world, data shifts are gradual, not sudden. Therefore, the loss balance between old and new data patterns is unlikely to change drastically. By continually applying the Marketplace algorithm, the loss for old and new data patterns should balance out shortly after a data shift occurs. However, this is just a hypothesis, and other factors I haven’t considered may be causing the decline in validation accuracy. Further investigation is needed to confirm this approach’s reliability.
Another factor to consider is the fixed learning rate used for continual learning. In traditional training, the learning rate is typically reduced over time to allow smaller, more precise adjustments, enabling the model to fine-tune the final decimal points of accuracy. With a fixed learning rate, the model may overshoot when only small adjustments are needed, especially when the loss gap is minimal. This forces the algorithm to select parameters that impact both old and new data. To address this, we could dynamically adjust the learning rate based on the loss gap between the new and original datasets. For example, using the variance or standard deviation of the loss gap to schedule the learning rate could allow the model to focus on fine-tuning when the loss gap is small, improving overall accuracy.
Finally, model capacity is another important factor. The current model is small, limiting the algorithm’s ability to select parameter changes that benefit the new data without negatively impacting the original dataset. I wonder if a larger model would yield different results.
What Does This Mean for the Future of Machine Learning?
If the potential impact of using the Marketplace algorithm for training is one, I would argue that its potential for continual learning is a thousand times greater—or more. While it appears effective with a limited dataset and a very small model, this does not guarantee success with larger models or more complex datasets. However, given the scale of inference—often millions or even billions of inferences per day—I believe we can make it work by leveraging the abundant probes provided by real-world model usage. Even if the approach is only viable for small models, I can envision many exciting applications. Here are some ideas:
Privacy-Friendly Machine Learning
Traditional machine learning often lacks privacy-friendliness. The conventional process involves collecting all user data, running a forward pass, collecting logits, performing a backward pass, and updating model parameters. This process is difficult to break down into smaller steps. For example, consider a mobile app that predicts a user’s blood pressure for the next day based on their current health data. The traditional approach requires collecting and anonymizing all user health data before keeping them for training.

A diagram showing that the traditional approach to training a model requires collecting all user data and storing it on the server with an anonymization process.
However, what can we do if regulations, such as HIPAA compliance, prohibit sending user data to the server?
One straightforward solution is to run the backward pass on the user’s mobile device to compute the gradient and send only the gradient to the server to update the model parameters. However, the backward pass is computationally expensive, and the gradient size is often as large as the model parameters, making it impractical to perform on a mobile device and transmit to the server. Even for smaller models designed for edge devices, this approach may still be too resource-intensive.

A diagram showing a naive approach to training a model on the user's device, requiring the gradient from the backward pass to be sent to the server.
Moreover, sharing gradient data risks leaking user information, as gradients can potentially be reverse-engineered to reconstruct the original data. However, the Marketplace algorithm offers a different approach. If the model is small enough, the user’s device can run a forward pass with a random path and different vendor deltas, then send only the path and logits to the server. The delta is generated from seed-based random numbers, making it easy to produce on the fly during the forward pass. If a label is available, only the loss needs to be sent, and the logits can be discarded. In cases where the label is provided naturally by the user after a prediction, this process avoids sending any local user data to the server.
Logits are typically small, containing concentrated information that is difficult to use to deduce the original user data. With loss, a single float value, it’s virtually impossible to reconstruct the user’s data, especially if the input data space is large. (Well, not so fast.. 😅 speaking from infosec background, with enough samples, it might still be possible to reconstruct the user’s data, but that’s another story)

A diagram showing a privacy-friendly approach to training a model on the user's device using the Marketplace algorithm. The device only sends the chosen random path and the loss or logits to the server.
From the server’s perspective, collecting enough forward paths and losses allows it to perform the steps outlined in the V2 article to generate the reconciled delta. This enables the server to update model parameters without accessing any user data. This approach has significant potential for privacy-friendly machine learning. Hey, Apple, I would be very interested in exploring this approach if I was you!😄
Tailored Model for Each User or Group Based on Usage Patterns
Some argue that marketplace algorithms may not perform well for larger models. I disagree, as they often overlook the significant differences in inference scale. With large-scale inference, I believe we can make it work one way or another; the only question is how. However, if the marketplace algorithm is indeed unsuitable for bigger models, what then? This led me to question whether we truly need large models.
The reason models are so large is that they aim to cover all possible scenarios. In reality, different users have distinct needs. What if we could train a model for each user without incurring extra costs? Or, at the very least, for a group of users? The exciting part is that the more users engage with the model, the better it becomes.
One potential application of a marketplace continual learning algorithm is to start with a smaller base model, divide use cases into different groups, and then let the continual learning process adapt to the specific needs of each group. This way, we can create models tailored to individual users or groups without significant additional costs.

A diagram showing that while a large model tries to cover all possible scenarios, a small model can be tailored to specific use cases.
Even if the model is large, techniques like LoRA can be used to fine-tune only a small part of the model, keeping costs low. The potential of this approach is highly promising.
Future Research Directions
Several questions remain unanswered in this field. Below, I outline some key areas for future exploration.
How does inferencing with random vendors and their deltas impact inference performance?
Currently, we observe no major differences in inference performance, likely due to the simplicity of our model and dataset. However, with more complex models and datasets, the impact may be more pronounced. Adding deltas to the original model weights requires careful consideration to avoid degrading inference performance, as we rely on accurate outputs for users.
How can we train a model that is more conducive to continual learning?
In our second experiment with the digit “9,” the model exhibited inertia, resisting outputting this digit even when it was excluded from the loss calculation. This raises the question: Can we train a model with reserved label slots for new classes to be more continual learning-friendly? Ideally, such a model would learn new data immediately without inertia. Beyond classification models, other approaches may also enhance continual learning capabilities.
Developing a dataset with data shift for testing continual learning
Our experiments currently rely on the MNIST dataset. I am not familiar with other datasets. I think MNIST is not ideal for testing novel concepts like continual learning. A more suitable dataset would incorporate data shift, divided into groups where each group exhibits slight variations from the previous one.

A diagram illustrating a dataset with data shift for testing continual learning.
Such a dataset would enable us to evaluate how well a model adapts to new data gradually during the continual learning process.
What are the limits of the Marketplace algorithm?
The Marketplace algorithm has shown promise with small models and simple datasets. However, its effectiveness with larger models and more complex datasets remains untested. While it demonstrates significant potential as a proof of concept, further experiments are needed to assess its performance in these scenarios. Given the scale of inference—often millions or billions of inferences per day—finding optimal parameters for updates is likely feasible, suggesting that these challenges are solvable.
Exploring privacy-friendly machine learning
It is often assumed that machine learning cannot prioritize privacy without compromising training. However, the Marketplace algorithm suggests otherwise, enabling privacy-friendly machine learning. This is particularly valuable in use cases like healthcare, where regulations such as HIPAA may prevent sending local user data to servers due to patient privacy concerns. The Marketplace algorithm’s continual learning approach allows models to learn through inference alone, without transmitting sensitive data.
My background in information security, from my master’s degree in computer science, informs my perspective on this topic. Techniques like blind signatures, homomorphic encryption, and oblivious transfer offer interesting ways for protecting data privacy while providing service to the users. I think similiarly, we can protect the privacy of the data while providing machine learning powered service to the users. Privacy-friendly machine learning warrants further exploration and could be the subject of an entire article or more.
Join the Research Effort!
For now this is still a solo research project. There are many exciting avenues to explore with this algorithm. As always, all my work is open-source under the MIT license and accessible to everyone:
https://github.com/LaunchPlatform/marketplace
Please feel free to contribute to the project, fork it, or conduct your own research. I believe this algorithm offers a fresh perspective on machine learning. And this is just the beginning. Even if I hit a dead end someday, someone with greater insight might find a way to make it work or draw inspiration from it to create something even better.
Final thoughts
That’s a tons of things I have done in the past few weeks. There are simply too many exciting avenues to explore with this algorithm. For now, I’ll take a short break to focus on my SaaS products (like BeanHub) for a short while. In the meantime, I’m considering the next direction for my research. Thank you for reading this article! I hope you found it at least somewhat inspiring. Stay tuned for upcoming articles. 😄