Since the last time I published the second MAZE (Massive Argumented Zonal Environments) article, I realized that the framework is getting more mature, but I need a solution to run it on a large scale. In the past, I built a bare metal Kubernetes cluster on top of a three-node mini PC interconnected with USB4. I have a retired workstation PC with NVIDIA GeForce RTX 2080 Ti. I wondered why not put this PC into the three-node Kubernetes cluster and configure Kubernetes to make CUDA work. Once I have one configured, extending the computing power capacity with more GPUs will be easier.
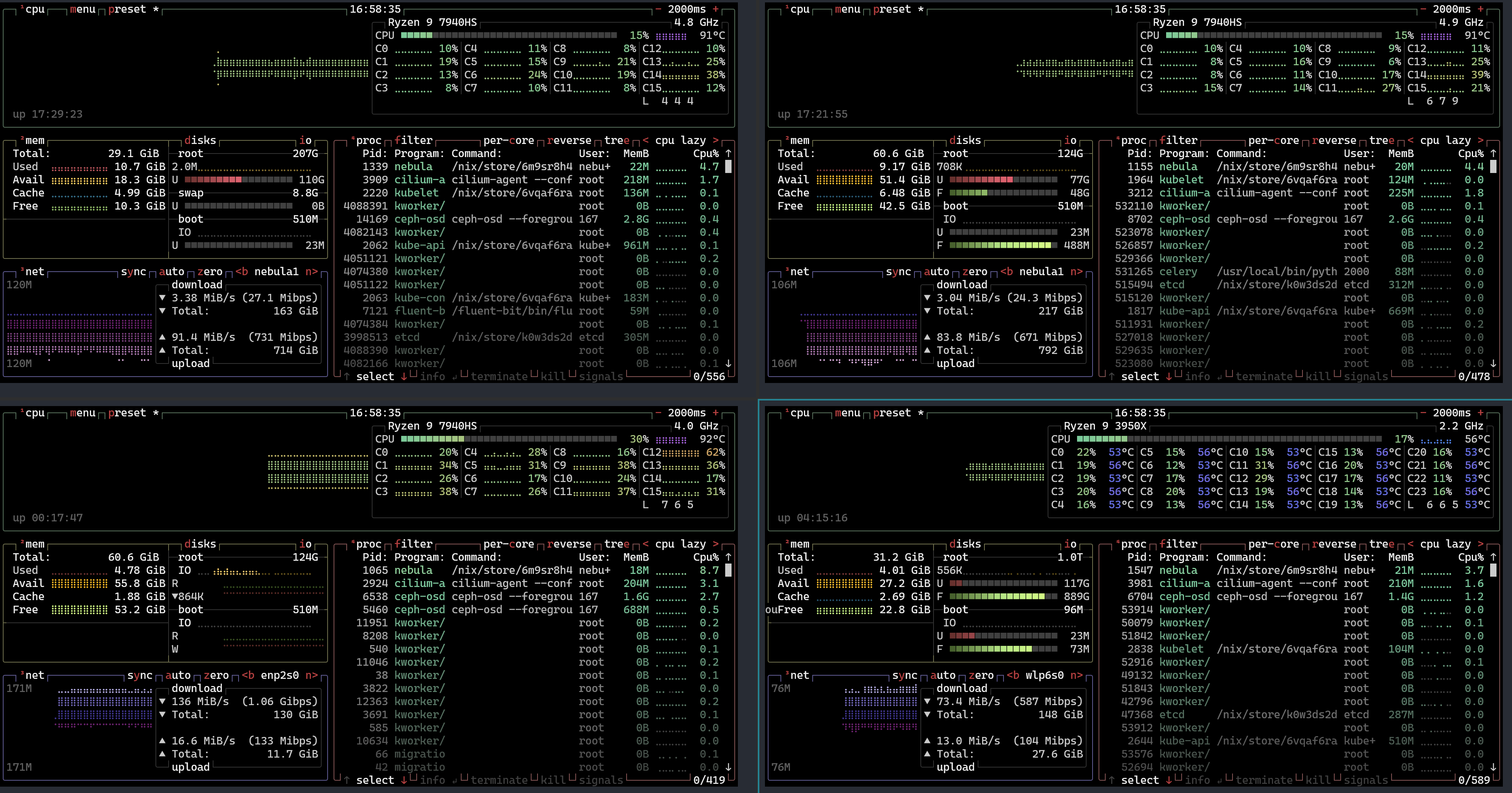
Screenshot of btop of my four-node Kubernetes cluster, with three mini PCs connected via USB4 and the newly added retired workstation sporting an Nvidia GeForce RTX 2080 Ti.
With that in mind, I took a week on this side quest. It turns out it’s way harder than I expected. I have learned a lot from digging this rabbit hole, and I encountered other holes while digging this one. Getting the Nvidia device plugin up and running in Kubernetes is hard. Not to mention, running on top of NixOS makes it even more challenging. Regardless, I finally managed to get it to work! Seeing it running for the first time was a very joyful moment.
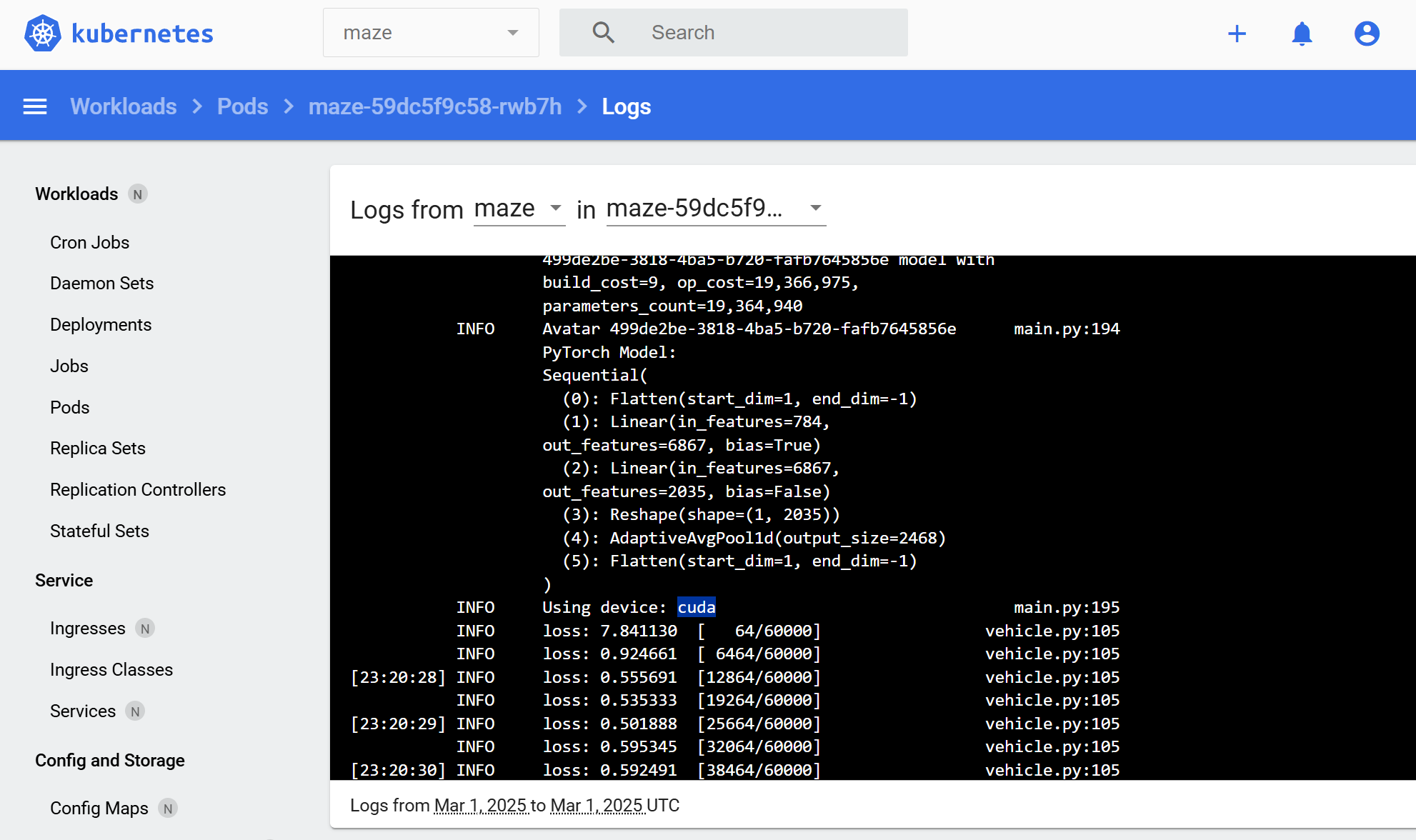
Screenshot of the Kubernetes dashboard shows the logs of a MAZE pod running an experiment on a CUDA device
An article like this could be helpful to someone as more software engineers are getting into machine learning. Running all of it on the cloud is a costly option. There are also privacy concerns for personal use, so Nvidia GPU on a local bare-metal Kubernetes cluster is still a very tempting option. Here, I would like to share my experience setting up a bare metal Kubernetes cluster with the Nvidia GPU CDI plugin enabled in NixOS.
Chain of rabbit holes
I want to make my Kubernetes support Nvidia GPU, not because I like it. I just need to find a way to scale MAZE to continue my research more efficiently. In software engineering, when you encounter a problem that requires dedicated time and effort to find the solution or root cause, I call it digging a rabbit hole. It’s a reference from Alice’s Adventures in Wonderland’s Down the rabbit hole.

Rabbit from Alice's Adventures in Wonderland, by John Tenniel
Interestingly, during the process of digging a rabbit hole, you would often find yourself needing to dig another due to a new obstacle. I call it the chain of rabbit holes. For example, I just heard in the All-in podcast they mentioned that for Elon Musk to build Gork in a short time frame, they had to
- Find a place for putting one hundred GPU
- Need power, so buy generators
- Need cooling, so buy portable liquid cooling
- Realize the need to smooth power usage, so install the Tesla powerpack
- …
This is a great example of a chain of rabbit holes. The ability to dig rabbit holes and solve hard problems down the chain boils down to two words:
Execution power
The reason for Deepseek’s recent successful story also boils down to execution power. They recently announced their customized distributed file system to optimize AI training. Their ability to dig rabbit holes like this or the previous PTX (Parallel Thread Execution) optimization shows great execution power.
It may sound obvious, but there are many interesting aspects to consider while digging rabbit holes. Of course, with constraints, one cannot dig all the rabbit holes, and it would take forever to finish the project. Also, not all rabbit holes are worth digging. Since this is an interesting topic but rarely mentioned, I would bring up a bit of my thought process on my decision going down each rabbit hole. Before that, let’s see the chain of rabbit holes I was digging in the past week:
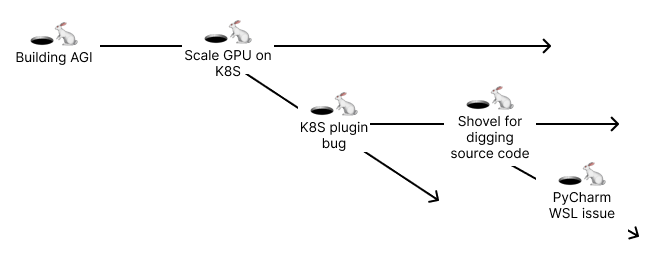
Diagram illustrating the chain of rabbit holes I encountered while setting up Nvidia GPU support on my Kubernetes cluster.
Running Kubernetes with NixOS
It is not a new rabbit hole I dug. I have already figured out how to deploy Kubernetes on NixOS as needed while building the three-node cluster. But since I didn’t mention details in the previous article, bringing up the details here makes sense.
I love NixOS and Nixpkgs. The ability to configure a whole operation system with just configuration files, making it reproducible, is simply amazing. Here’s an example of a hello world NixOS config file:
{ config, lib, pkgs, ... }:
{
imports =
[ # Include the results of the hardware scan.
./hardware-configuration.nix
];
# Use the systemd-boot EFI boot loader.
boot.loader.systemd-boot.enable = true;
boot.loader.efi.canTouchEfiVariables = true;
system.stateVersion = "24.11";
}
While terrific, it doesn’t come without drawbacks, particularly considering deploying it to multiple machines.
The first problem is that while most configurations would be the same for a machine, many things, such as the hostname, would still be different.
One cannot write a simple configuration and apply it everywhere on all the machines.
NixOS generates configuration files in the /etc folder as read-only files with symbolic links to the actual config files in the /nix/store folder.
Screenshot of the output from listing /etc folder shows many symbolic links
I found a tool called deploy-rs for deploying to different machines with slightly different configurations. It allows you to define configurations for each machine with customization and deploy them easily via SSH. Usually, this is good enough with simple stuff like hostnames or Linux configurations. However, running a full-blown Kubernetes cluster is yet another story. Just PKI (Public key infrastructure) certification generation and deployment are troublesome.
Generating Kubernetes certificates also implies creating secret keys and deploying them into each node. NixOS is very good at making a predictable environment with immutable packages and configuration files, but dealing with centralized secret values distribution is not ideal. I certainly don’t want to commit my secret key to Git history along with the NixOS configuration file. Therefore, we need another approach to deploy dynamically generated configurations and secret keys to all those machines.
I am pretty familiar with Ansible because I used it a lot in the past and even contributed to the omit filter many years ago. So when I encountered this problem, Ansible came first into my mind for deploying Kubernetes configuration files and generating the PKI secrets plus certificates. I don’t plan to cover too much detail, but here’s what I do. I replace the Kubernetes services config in the NixOS configuration to make them read from a local file as the arguments like this:
{
config,
pkgs,
lib,
...
}: {
systemd.services.kubelet = {
serviceConfig = {
Restart = mkForce "always";
RestartSec = mkForce "20s";
EnvironmentFile = "/var/lib/k8s/kubelet.env";
ExecStart = mkForce ''${pkgs.bash}/bin/bash -c "${pkgs.kubernetes}/bin/kubelet $_KUBE_ARGS"'';
};
};
# ... other k8s services
}
Then, I have an Ansible playbook that will SSH into all machines and generate the corresponding arg and config files, along with PKI certificates and secret values.
Here’s an example of the Ansible Jinja2 template for generating the /var/lib/k8s/kubelet.env shown in the above Nix example:
{{ ansible_managed | comment }}
_KUBE_ARGS={{
(
[
"--root-dir=/var/lib/k8s/kubelet",
"--config=/var/lib/k8s/kubelet/config.yaml",
"--kubeconfig=/var/lib/k8s/pki/kubelet.conf",
"--image-credential-provider-config=/var/lib/k8s/kubelet/image-credential-provider.yaml",
"--image-credential-provider-bin-dir=/run/current-system/sw/bin",
"--runtime-cgroups=/system.slice/containerd.service",
"--node-ip={}".format(nebula1_node_ip | ansible.utils.ipaddr('address')),
"-v", (kubelet_log_level | default(1) | quote),
]
+ (["--node-labels={}".format(','.join(node_labels))] if node_labels is defined else [])
) | join(" ") | quote
}}
You may ask where you put the secret value. I use Sops and its Ansible plugin. All the values are encrypted using a GPG key.
- name: Deploy k8s cluster
hosts: all
pre_tasks:
- import_tasks: tasks/sops.yaml
tags: ["sops", "always"]
tasks:
- name: Do something with the secret value
ansible.builtin.debug:
msg: "{{ secrets.my-value }}"
# ...
By combining NixOS, Ansible, and Sops, I can easily deploy to as many bare metal machines as I want as a Kubernetes cluster. I even built a NixOS live CD environment for a USB thumb drive to help speed up the bootstrapping process. But this article already has too much content, so I will leave it for text time.
Kubernetes with Nvidia GPU CDI plugin explained
Running a pod on Kubernetes with Nvidia GPU exposes sounds straightforward. How hard could it be? But when you look closer, it immediately gives you a headache. Just the sheer number of terms may overwhelm some people. Be it CRI, CDI, nvidia-container-toolkit, libnvidia-container, and all the confusing terms at first glance.
Although I have plenty of experience in Kubernetes and container technologies, it also took me a while to fully understand those terms and how they are interconnected. Let’s first see the big picture of how everything works together, and then we will explore the details of how each component works together.

Schematic overview of the Nvidia GPU integration architecture within Kubernetes on NixOS, showcasing the interplay between Container Runtime Interface (CRI), Container Device Interface (CDI), nvidia-container-toolkit, and the k8s-device-plugin.
The official document from Nvidia about the architecture will also help you understand.
Container Runtime Interface
As you are familiar with Kubernetes, there are so many CXI terms, such as CNI (Container Network Interface) or CSI (Container Storage Interface); they are all well-defined interfaces that open up the implementation details of fundamental Kubernetes functionalities to third parties. For instance, CNI is for networking, and CSI is for data storage.
Likewise, CRI stands for Container Runtime Interface, the plugin interface for adopting different container management systems. The most well-known ones are Containerd and CRI-O. With NixOS, you can change its settings like this to make it support Nvidia runtime:
virtualisation.containerd = {
settings = {
plugins = {
"io.containerd.grpc.v1.cri" = {
enable_cdi = true;
cdi_spec_dirs = ["/etc/cdi" "/var/run/cdi"];
containerd = {
default_runtime_name = "nvidia";
runtimes = {
nvidia = {
privileged_without_host_devices = false;
runtime_type = "io.containerd.runc.v2";
options = {
BinaryName = "${pkgs.nvidia-container-toolkit}/bin/nvidia-container-runtime";
};
};
};
};
};
};
};
};
nvidia-container-toolkit
We just mentioned CRI above. One of the jobs of nvidia-container-toolkit is facilitating the CRI interface between Kubernetes’ CRI and the container runtime. What is a container runtime? Usually, it’s a runtime provided as a command line tool to launch an isolated container process by creating new Linux namespaces and mounting host paths into the container. The most commonly used ones are runc and crun.
The nvidia-container-toolkit ship its own container runtime, the nvidia-container-runtime executable.
It may sound confusing. Why did I say nvidia-container-runtime is a container runtime but also facilitates the CRI interface between Kubernetes and the container runtime?
Well, the thing is, nvidia-container-runtime doesn’t implement the full-blown container runtime.
It’s a thin layer on top of other lower-level runtime implementations such as runc or crun.
When Containerd or CRI-O invokes Nvidia’s CRI, the OCI containers’ spect will be modified to expose the needed Nvidia drivers, devices, and executables like nvidia-smi into the container.
Once the spec file is modified, it will call the underlying crun or runc to do the actual Linux namespace management and all the other container good stuff.
So, it’s like a proxy (or some may prefer to call it a shim) between the CRI and the runtime, performing a few modifications to the traffic passing through.

Screenshot shows Containerd passes the original OCI spec file config.json to nvidia-container-runtime, and then nvidia-container-runtime modifies the config.json file and passes it along to runc
Other than the container runtime, the nvidia-container-toolkit project also provides utility tools for generating various configurations. Such as this one for generating container runtime configuration for Containerd:
nvidia-ctk runtime configure --runtime=containerd
libnvidia-container
There are some confusing parts about this repository.
While its name says libnvidia-container, they don’t use it as a library like all other projects with lib prefixes would usually do; at last, from the perspective of the Kubernetes plugin.
Instead, it provides an executable, nvidia-container-cli. The main purpose of this executable is to collect and provide information about Nvidia drivers, devices, and executables to be injected into the container environment.
Usually invoked directly from the nvidia-container-runtime’s hook command.
I guess they need to use the same logic somewhere in Nvidia’s container-relative projects, and that might be why they need to make it a library.
This command-line tool is used when using Nvidia as container runtime directly without CDI support. Otherwise, it appears that if we take the CDI route, this command-line tool is not used at all.
Container Device Interface
Similar to CRI, it’s also a well-defined plugin for Kubernetes. Instead of providing container runtime functionalities, it offers particular device resources to expose to the container environment. With Nvidia’s CDI (Container Device Interface) implementation, we can then expose GPU devices as resources in the container.
In addition to Kubernetes, a container CLI tool like Podman can also use proper CDI configuration to have an Nvidia GPU inside the container.
$ podman run --device nvidia.com/gpu=all alpine nvidia-smi
Sat Mar 1 23:51:00 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 565.77 Driver Version: 565.77 CUDA Version: 12.7 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 2080 Ti Off | 00000000:0A:00.0 On | N/A |
| 46% 57C P2 103W / 260W | 3998MiB / 11264MiB | 33% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
The --device argument with nvidia.com/gpu=all value tells podman to look for the resource (device) type nvidia.com/gpu, and we want all of it exposed inside the container.
k8s-device-plugin
With nvidia-container-toolkit and libnvidia-container, now it’s possible to run a container with Nvidia GPU exposed inside a container, but then we still need a way to let Kubernetes know there’s nvidia.com/gpu such resource available for pods to use, and we need to know which nodes have them, how many are available, how many are in use, and what types.
The k8s-device-plugin is here to solve those problems.
The k8s-device-plugin deployed in the Kubernetes cluster has DaemonSet to check for available Nvidia GPU devices on each node, report on them, and manage that information with the Kubernetes API server.
Dig this hole first - build nix-playground for hacking and patching any source code easily
Now we have the background knowledge about what’s what in the context of Nvidia GPU on Kubernetes.
Do you think it’s about time to discuss adding Nvidia GPU support to your bare-metal Kubernetes cluster?
Well, not so fast. As I thought it shouldn’t be too hard, just deploy the k8s-device-plugin as a helm chart, generate and modify configurations as described in Nvidia’s official documents, and it should be good to go, right?
Unfortunately, I saw many errors immediately right after I did so. Like this one from nvdp-nvidia-device-plugin DaemonSet:
symbol lookup error: /nix/store/nqb2ns2d1lahnd5ncwmn6k84qfd7vx2k-glibc-2.40-36/lib/libc.so.6: undefined symbol: __tunable_is_initialized, version GLIBC_PRIVATE
It turns out we need to dig deeper 😅.

The We Need To Go Deeper meme from the Inception movie
I am the type of engineer who enjoys digging rabbit holes most of the time and learns a lot from doing so. Many people don’t understand software engineering, so I have said countless times that reading code is way harder than writing code. In the era of AI, generating code makes it even harder to read. And reading source code upstream is critical for solving hard problems. Sometimes, you are lucky, and there are easy ways to work around problems, but sometimes, there’s no easy way around but to find the root cause.
An error like this one is very tricky because the executable crashes immediately after it starts the container process in the Linux namespace.
Usually, when seeing an error like this, I just exec or debug into the container with a shell to see what’s happening.
But it won’t work in this case because all executables crash like that in the container, even for /bin/sh.
I had no choice but to read the source code of Nvidia’s container projects, and I needed to modify the code to figure out what was going on. Unfortunately, modifying source code and making a custom build is annoying. Just to get the project to build could take hours. You need to read the instructions to install the required dependencies. Sometimes, there are very specific versions of those dependencies or build environments you need to get. Very often, it could take hours or even a few days just to get a project to build, depending on how complex the project is.
I wish there was a tool to help me hack the source code of any open-source projects and build them quickly with my code changes so I could try things out quickly. Then I realized, okay, why not just build one myself? Obviously, this is yet another rabbit hole to dig from the original one. But if it works, this could be super useful down the road. Considering the potential productivity gains and the leverage this tool could have. I’ve decided to context-switch to digging this rabbit hole shortly.
I love NixOS and Nixpkgs because they’re a build tree containing almost all major open-source software, from the Linux kernel to a utils command-line tool. As far as I know, nothing else like this allows you to build the whole system from end to end under the same framework. Thanks to the nature of this tool, it has the building scripts ready in Nix for all the projects I want to look into, including the nvidia-container-toolkit and libnvidia-container.
Since each Nixpkgs package is just the artifact of yet another Nix’s derivation, which describes how to build the project and all its dependencies in a pure data format (ATerm), I should be able to extract the source code from it. With that in mind, I quickly built a prototype to try out, which I called nix-playground. And yes, I open-sourced it under the MIT license. You can use it as a playground to easily play around and patch any open-source project. Here’s some example:
# checkout libnvidia-container package source code locally
np checkout nixpkgs#libnvidia-container
# modify the code
vim checkout/src/cli/main.c
# build the package with changes you made in the checkout folder and try it out
np build
# output the patch for applying on the production environments
np patch > bugfix.patch
# clean up the generated files
np clean
I spent two days fixing some corner cases on this open-source project. It now works great! I have the best shovel for digging the k8s-device-plugin crashing bug. It’s time to go back and dig the previous rabbit hole!
Hunting the k8s-device-plugin crashing bug
One problem I faced when debugging the k8s-device-plugin crashing issue was that I didn’t know how it worked in detail. So, I inserted many log writing lines into the code to see how it worked. Some may say hey, you can use a debugger. Well, yeah, I know, but very often, it’s also very tedious to set up a debugger. I would use it if it comes in handy; otherwise, I would just insert logs.
I have been using Grok 3 for a while since its launch. I really enjoy it. Sometimes, it provides made-up or wrong results but still very often provides sound analytics. I never intend to rely on it fully. I take it as more like riding a bike. I am still the one who rides the bike, not the bike riding me. The code it generates still can’t always meet my standards. When I jumped into debugging the Nvidia stuff, I quickly realized, well, despite that, I don’t trust the quality of the generated code from AI models, but if it’s throw-away code, it doesn’t matter. I don’t care about the quality as long as it works. Therefore, I asked Grok 3 to help me insert log entries into the source code I pasted from Nvidia’s GitHub repository, and it did a wonderful job.
Thanks to Grok 3, I no longer have to manually write log entries for debugging purposes and can instead focus on solving the actual problem. Here’ss the log file generated from the update ldconfig hook patched by Grok 3.
2025-02-26T17:23:51-08:00: Starting update-ldcache
2025-02-26T17:23:51-08:00: Loading container state from
2025-02-26T17:23:51-08:00: Loaded container state
2025-02-26T17:23:51-08:00: Getting container root
2025-02-26T17:23:51-08:00: Determined container root: /home/fangpen/.local/share/containers/storage/overlay/5c92b5c6053ce2643bcbe516adf268ecdf03244ab3a514ff2e539b6017dbcf0e/merged
2025-02-26T17:23:51-08:00: Resolving ldconfig path from /nix/store/29mb4q8b5306f4gk2wh38h0c1akb0n97-glibc-2.40-36-bin/bin/ldconfig
2025-02-26T17:23:51-08:00: Resolved ldconfig path: /nix/store/29mb4q8b5306f4gk2wh38h0c1akb0n97-glibc-2.40-36-bin/bin/ldconfig
2025-02-26T17:23:51-08:00: Checking for /etc/ld.so.cache in container
2025-02-26T17:23:51-08:00: /etc/ld.so.cache exists, will update cache
2025-02-26T17:23:51-08:00: Creating config in /etc/ld.so.conf.d for folders: /nix/store/x5522a7p46nnbwxjv8w942p6qps7x0lw-nvidia-x11-565.77-6.6.79/lib
2025-02-26T17:23:51-08:00: Creating /etc/ld.so.conf.d if not exists
2025-02-26T17:23:51-08:00: Created /etc/ld.so.conf.d
2025-02-26T17:23:51-08:00: Creating temp config file in /etc/ld.so.conf.d
2025-02-26T17:23:51-08:00: Created temp config file: /home/fangpen/.local/share/containers/storage/overlay/5c92b5c6053ce2643bcbe516adf268ecdf03244ab3a514ff2e539b6017dbcf0e/merged/etc/ld.so.conf.d/nvcr-4265966838.conf
2025-02-26T17:23:51-08:00: Writing folders to config file: /nix/store/x5522a7p46nnbwxjv8w942p6qps7x0lw-nvidia-x11-565.77-6.6.79/lib
2025-02-26T17:23:51-08:00: Added folder: /nix/store/x5522a7p46nnbwxjv8w942p6qps7x0lw-nvidia-x11-565.77-6.6.79/lib
2025-02-26T17:23:51-08:00: Setting permissions on config file to 0644
2025-02-26T17:23:51-08:00: Set permissions on config file
2025-02-26T17:23:51-08:00: Preparing ldconfig arguments: ldconfig -r /home/fangpen/.local/share/containers/storage/overlay/5c92b5c6053ce2643bcbe516adf268ecdf03244ab3a514ff2e539b6017dbcf0e/merged -C /etc/ld.so.cache -f /etc/ld.so.conf
2025-02-26T17:23:51-08:00: Executing ldconfig with args: ldconfig -r /home/fangpen/.local/share/containers/storage/overlay/5c92b5c6053ce2643bcbe516adf268ecdf03244ab3a514ff2e539b6017dbcf0e/merged -C /etc/ld.so.cache -f /etc/ld.so.conf
With the logs, I tried things quickly and understood the flow of the code. However, since the problem happens inside the container namespaces, I cannot view them from my non-namespace environment. I need to get a shell inside the namespace to better understand what’s going on. So, after I narrowed down the problem to the update ldconfig hook, I added a long sleep before the Nvidia container runtime makes the exec call to ldconfig so that I have time to look into it.
The createContainer hook configuration at /var/run/cdi/nvidia-container-toolkit.json:
{
"_": "// ...",
"hooks": [
{
"hookName": "createContainer",
"path": "//nix/store/il5kz2p67hdd05c9gmg8m5c5l8gbrk90-container-toolkit-container-toolkit-1.15.0-rc.3/bin/nvidia-ctk",
"args": [
"nvidia-ctk",
"hook",
"update-ldcache",
"--ldconfig-path",
"/nix/store/29mb4q8b5306f4gk2wh38h0c1akb0n97-glibc-2.40-36-bin/bin/ldconfig",
"--folder",
"/nix/store/x5522a7p46nnbwxjv8w942p6qps7x0lw-nvidia-x11-565.77-6.6.79/lib"
]
}
]
}
After the hook sleeps and hangs, I ran
$ lsns
NS TYPE NPROCS PID USER COMMAND
( ... omit ...)
4026533991 mnt 1 388163 fangpen /bin/sh
4026533992 uts 1 388163 fangpen /bin/sh
4026533993 ipc 1 388163 fangpen /bin/sh
4026533994 pid 1 388163 fangpen /bin/sh
4026533995 cgroup 1 388163 fangpen /bin/sh
To find out the pid of the container process, I just launched via podman to reproduce the bug. Then, I run this to attach a shell into the namespace:
sudo enterns -t <CONTAINER_PID> -a /bin/sh
Next, I ran the ldconfig command, which is supposed to run with the -p argument to see the current ldconfig cache.
$ ldconfig -p
131 libs found in cache `/etc/ld.so.cache'
( ... omit ...)
libc.so.6 (libc6,x86-64, OS ABI: Linux 3.2.0) => /lib64/libc.so.6
( ... omit ...)
Cache generated by: ldconfig (GNU libc) stable release version 2.34
Then, run the ldconfig without -p again to update cache and then with -p again to see the current cache:
$ ldconfig -r /home/fangpen/.local/share/containers/storage/overlay/3e2b7a6d05ca228fafe39b47a19952d4b81a9c413618c66a7013d794e4db3d96/merged -C /etc/ld.so.cache -f /etc/ld.so.conf -p
64 libs found in cache `/etc/ld.so.cache'
( ... omit ...)
libc.so.6 (libc6,x86-64) => /nix/store/nqb2ns2d1lahnd5ncwmn6k84qfd7vx2k-glibc-2.40-36/lib/libc.so.6
( ... omit ...)
Cache generated by: ldconfig (GNU libc) stable release version 2.40
Oops. All the caches are pointing to libraries injected by the Nvidia runtime container, including glibc. I guess the glibc compiled inside the plugin container image is different from the one shipped with the Nvidia driver in the Nix store. As a result, any executable that relies on glibc would then link to the wrong one, and literally, almost all executables would rely on glibc, and therefore, they all crash immediately.
After learning the root cause, I quickly drafted an issue, reported it to Nvidia’s nvidia-container-toolkit repository, and found an easy fix.
Most containers come with the config file in /etc/ld.so.conf.d pointing to the existing library paths.
The Nvidia runtime hook generates its own config file pointing to the library path provided in the argument.
But without the one pointing to the existing library path, there will only be a cache pointing to the injected lib.
To solve the problem, I created a PR with a config file pointing to /lib64.
RUN echo "/lib64" > /etc/ld.so.conf.d/lib64.conf
It was just a line code change, and it took me a few days to find out, including building the nix-playground tool 😅 That’s why one should never measure productivity with the number of lines added.
The missing RuntimeClass
Suppose you follow many online guides about running Kubernetes pods with Nvidia drivers. In that case, you may think you should be able to run it after you update the Containerd configuration to include the Nvidia CRI and set it as the default like this:
[plugins."io.containerd.grpc.v1.cri"]
default_runtime_name = "nvidia"
# other stuff ..
Unfortunately, it doesn’t work. I haven’t dug into this yet, but according to Nvidia’s k8s-device-plugin readme page:
If the nvidia runtime should be set as the default runtime (with non-cri docker versions, for example), the –set-as-default argument must also be included in the commands above. If this is not done, a RuntimeClass needs to be defined.
It’s just one line in the README, and they’re very easy to overlook. So, without an explicit RuntimeClass defined and assigned to a pod in Kubernetes, it won’t pick up the Nvidia runtime. I didn’t have time to find out how to make a runtime default on a node yet, but for now, I had to define a RuntimeClass like this:
apiVersion: node.k8s.io/v1
kind: RuntimeClass
handler: nvidia
metadata:
name: nvidia
Then, I will assign the runtimeClassName to it so that it will pick up my CRI configuration for Containerd.
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
# the `runtimeClassName` is needed, otherwise default runtime will still be used
runtimeClassName: nvidia
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda12.5.0
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPU
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
Yet another rabbit hole - PyCharm cannot open my WSL NixOS anymore
Interestingly, after the recent update, my PyCharm stopped working with my Python projects in my NixOS distro, WSL (Windows Subsystem Linux). While it sounds a bit unrelated to the main focus of getting the Nvidia GPU to run on Kubernetes, I needed to build nix-playground in Python, and it can only work in a Linux environment. I am bringing this up because this is the third level deep rabbit hole from Nvidia GPU on Kubernetes.
I reported this problem a while back, but I decided to dig this hole while building nix-playground because not being able to use PyCharm with WSL projects greatly impacts my productivity.
After digging briefly, I realized that PyCharm expected many executables at certain locations, such as in /usr/bin.
I addressed the problem by adding them to WSL NixOS config’s extraBin.
{
config,
lib,
pkgs,
...
}: {
wsl = {
enable = true;
extraBin = with pkgs; [
{src = "${coreutils}/bin/mkdir";}
{src = "${coreutils}/bin/cat";}
{src = "${coreutils}/bin/whoami";}
{src = "${coreutils}/bin/ls";}
{src = "${busybox}/bin/addgroup";}
{src = "${su}/bin/groupadd";}
{src = "${su}/bin/usermod";}
{src = "${busybox}/bin/busybox";}
{src = "${busybox}/bin/chmod";}
{src = "${busybox}/bin/cp";}
{src = "${busybox}/bin/cut";}
{src = "${busybox}/bin/getent";}
{src = "${busybox}/bin/head";}
{src = "${busybox}/bin/mktemp";}
{src = "${busybox}/bin/rm";}
{src = "${busybox}/bin/sed";}
{src = "${busybox}/bin/tail";}
{src = "${busybox}/bin/uname";}
{src = "${busybox}/bin/which";}
];
};
The rule of thumbs for digging the rabbit holes
Now, you’ve seen how I dug many rabbit holes in the past week. I tried to summarize my approach to digging the chain of rabbit holes:
- Consider the productivity impact. If it provides a great positive impact within a manageable timeframe, do it as soon as possible (nix-playground as a great example)
- Not all rabbit holes are worth digging; consider the cost-effect ratio. For example, I won’t jump into learning PTX and optimizing my MAZE code before it runs on a huge scale.
- Evaluate the timeframe of digging a hole to carefully decide whether to go down a hole. Sometimes, it’s hard to tell from the surface; a quick prototype and probing could help determine how hard it is.
- Enjoy digging rabbit holes because it’s the best way to learn new things
Final thoughts
I intentionally left out many details from this article because otherwise, it would be too long. If anyone is interested in learning more about running Nvidia CDI on a local Kubernetes cluster, please leave a comment and let me know. I am considering open-sourcing some of my work to make it much easier for anyone to have a local Kubernetes cluster enabled with Nvidia CDI.
This deviates a bit from building MAZE, but the outcome is great! Now I have an infra for running MAZE on a bigger scale—well, at least slightly bigger on the scale I can afford 😅 There are still other rabbit holes, like power consumption. With the constraints, I can only try to be creative.
Next, I will go back to improving MAZE and soon publish the third MAZE article. I have been running the experiment for the past week, and it has already accumulated some data with updated MAZE code, including mutations and some other good stuff. Likewise, I will publish the data along with the next article. I am still thinking about the next focus of the following research. I have some interesting ideas for eliminating backpropagation with the MAZE approach. I am also thinking that maybe it’s time to introduce more freedom (more operations) to MAZE’s neuron network so that I can break the accuracy barrier it’s facing. Anyway, we will see.
Regardless, thanks for reading. I hope you like my journey of digging the rabbit hole and sharing knowledge about running Nvidia GPU on Kubernetes. Please help me share this article if you find it interesting. Stay tuned because we will have tons of fun on the journey of learning machine learning by building a novel project like MAZE! 😄