I’ve been diving into machine learning projects lately, and I enjoy it a lot. However, one thing bothers me: I lack the computing power to test many interesting ideas. In my previous article for CakeLens, I designed and trained a model to detect AI-generated videos. But due to limited local computing power, I had to rent H100/A100 GPUs from Modal to experiment with different approaches. And it’s not cheap:
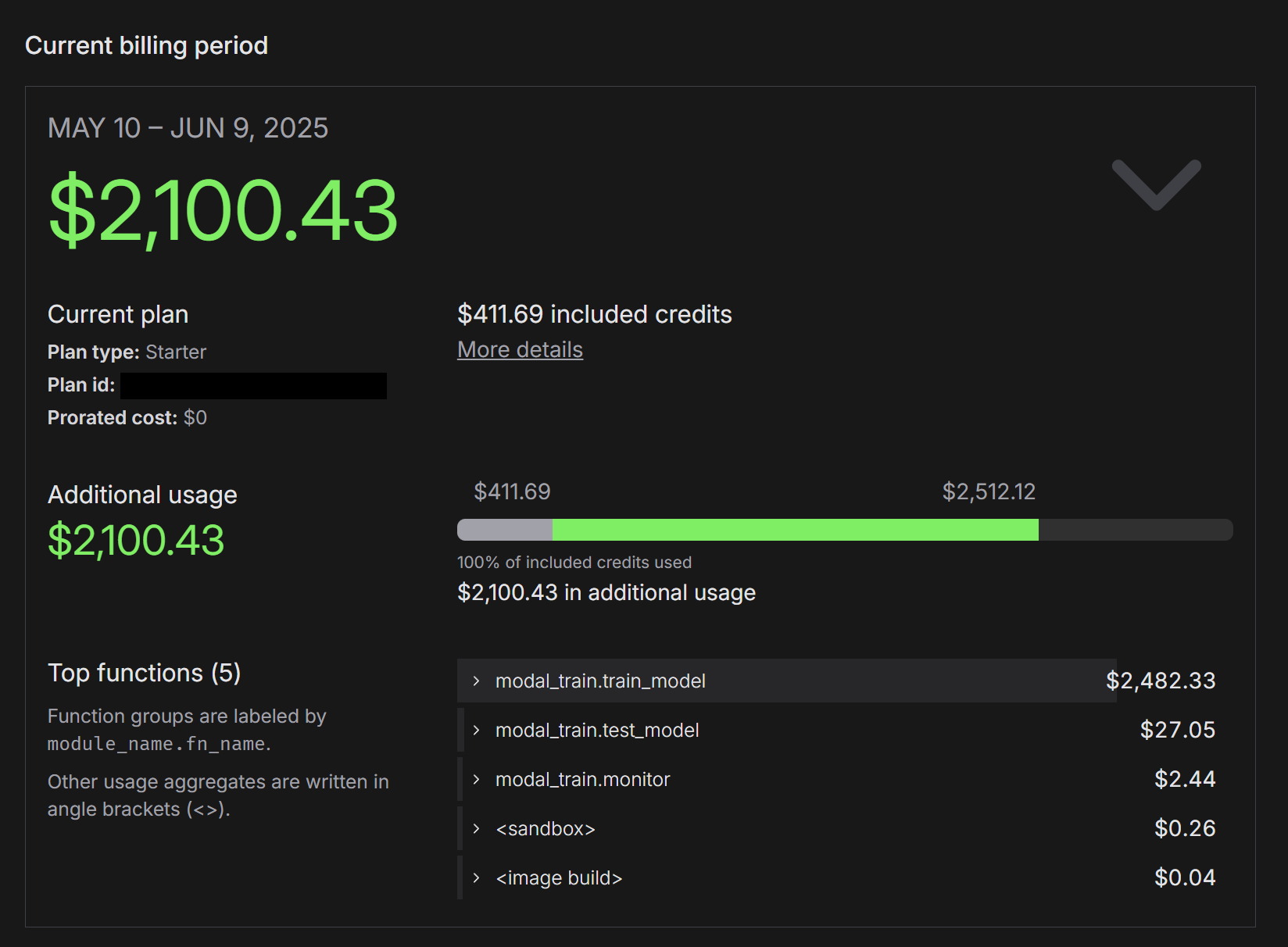
Screenshot of Modal's billing dashboard showing the total cost as $2.1K
My PC has an RTX 4090, so I could run training locally. However, memory constraints make it painful to train larger models. Even when a model fits on the GPU, the intensive computation consumes all GPU resources, rendering my PC unusable. To solve this, I need more local computing power to run machine learning experiments without breaking the bank.
My first idea was to buy another RTX 4090 or perhaps an RTX 5090. I checked prices online and was shocked. I bought my current 4090 for around $2,000 USD, but now they’re selling for $3,600 on Amazon. That’s insane! 🤯
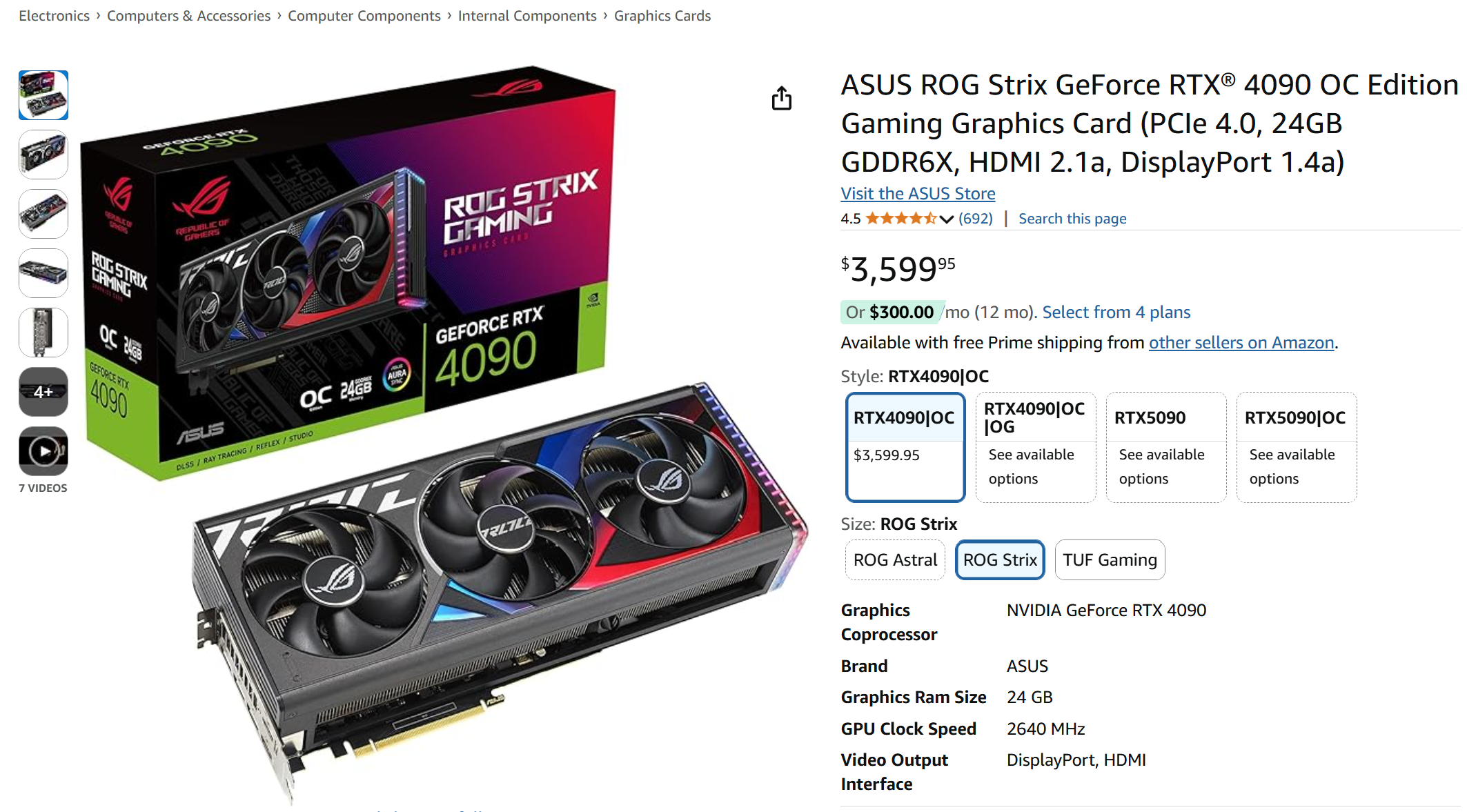
Screenshot of Amazon product page, featuring Asus ROG Strix RTX 4090 GPU selling at $3,599.95
Curious about the cost of an H100 for my home office, I checked its price:
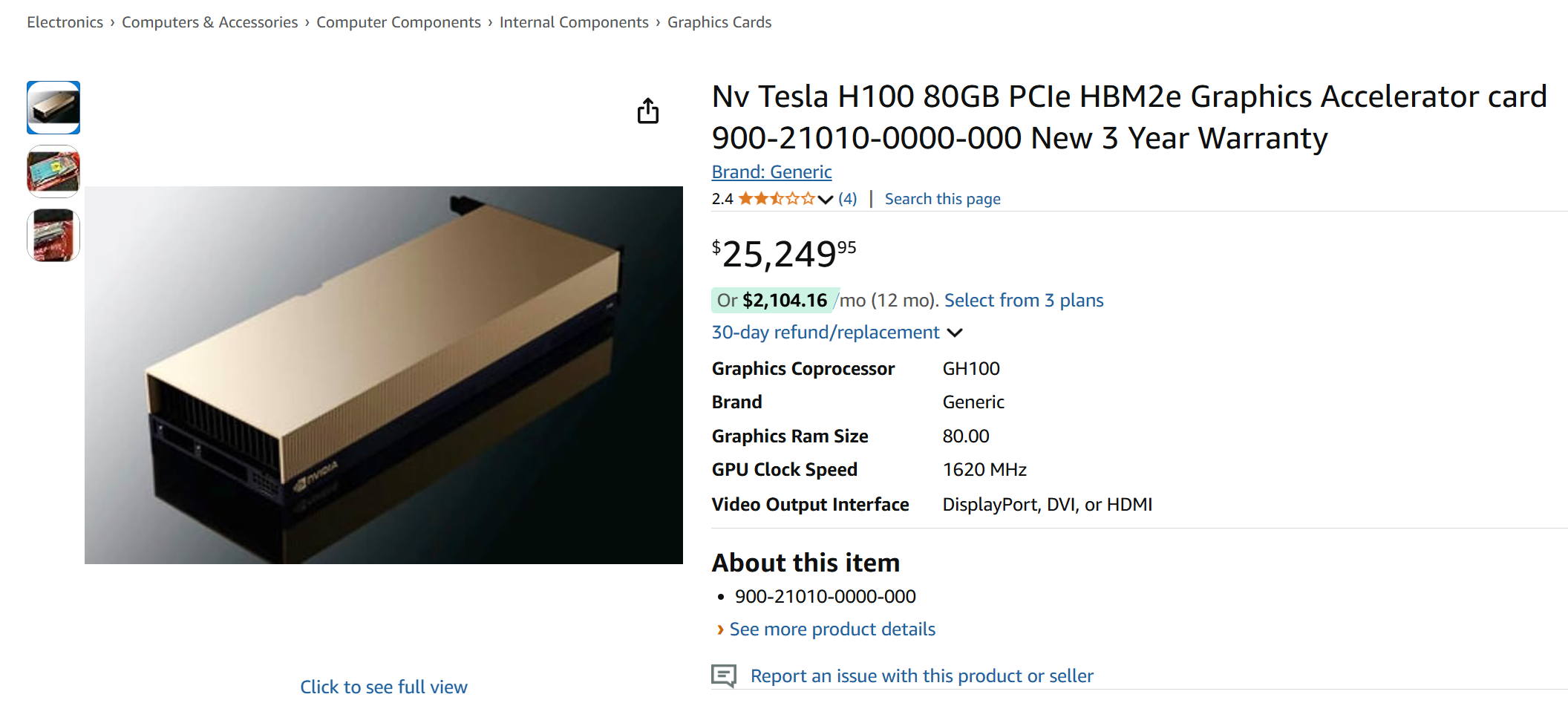
Screenshot of Amazon product page, featuring Nvidia Tesla H100 GPU selling at $25,249.95
Heh, you know what? I’m not planning to sell two KDNYs I have accumulated just yet 😅.
I don’t have the budget for more Nvidia GPUs right now, but I still want a local setup to experiment at a lower cost. One day, while browsing X, I found a post by Tinygrad showcasing their gradient functions defined in just 40 lines of code.
A X post by @__tinygrad__ showcasing gradients for backprop defined in just 40 lines
I tried it, and it was impressive—no dependencies, just an instant install with uv.
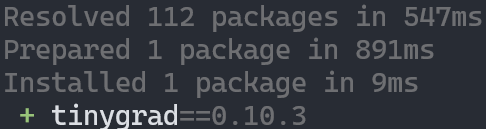
Screenshot of installing tinygrad with uv shows it only takes 9ms
After researching further, I really liked Tinygrad’s concept. It’s like the RISC (Reduced Instruction Set Computer) of machine learning, while PyTorch feels more like CISC (complex instruction set computer). I appreciate its clean, minimalist design, and it seems to support AMD GPUs well.
This made me wonder: why does everyone say Nvidia GPUs are the go-to for machine learning? They claim Nvidia’s strength lies in its software. Hmm, is that true? 🤔 Or, as some might say, is it a skill issue? 🤣
I’m not sure, but I wanted to find out. I’m curious about Tinygrad’s pre-built AMD training workstation. It’s tempting, but it’s outside the budget I can allocate, and it’s too bulky for my home office.

Screenshot of Tinybox, a pre-built machine learning work station by the tiny corp featuring AMD and Nvidia GPU options. The AMD option is selling at $15,000 USD
Looked at the GPUs they are using, the AMD 7900XTX seemed mature. Best of all, the price was reasonable—just $1,100:
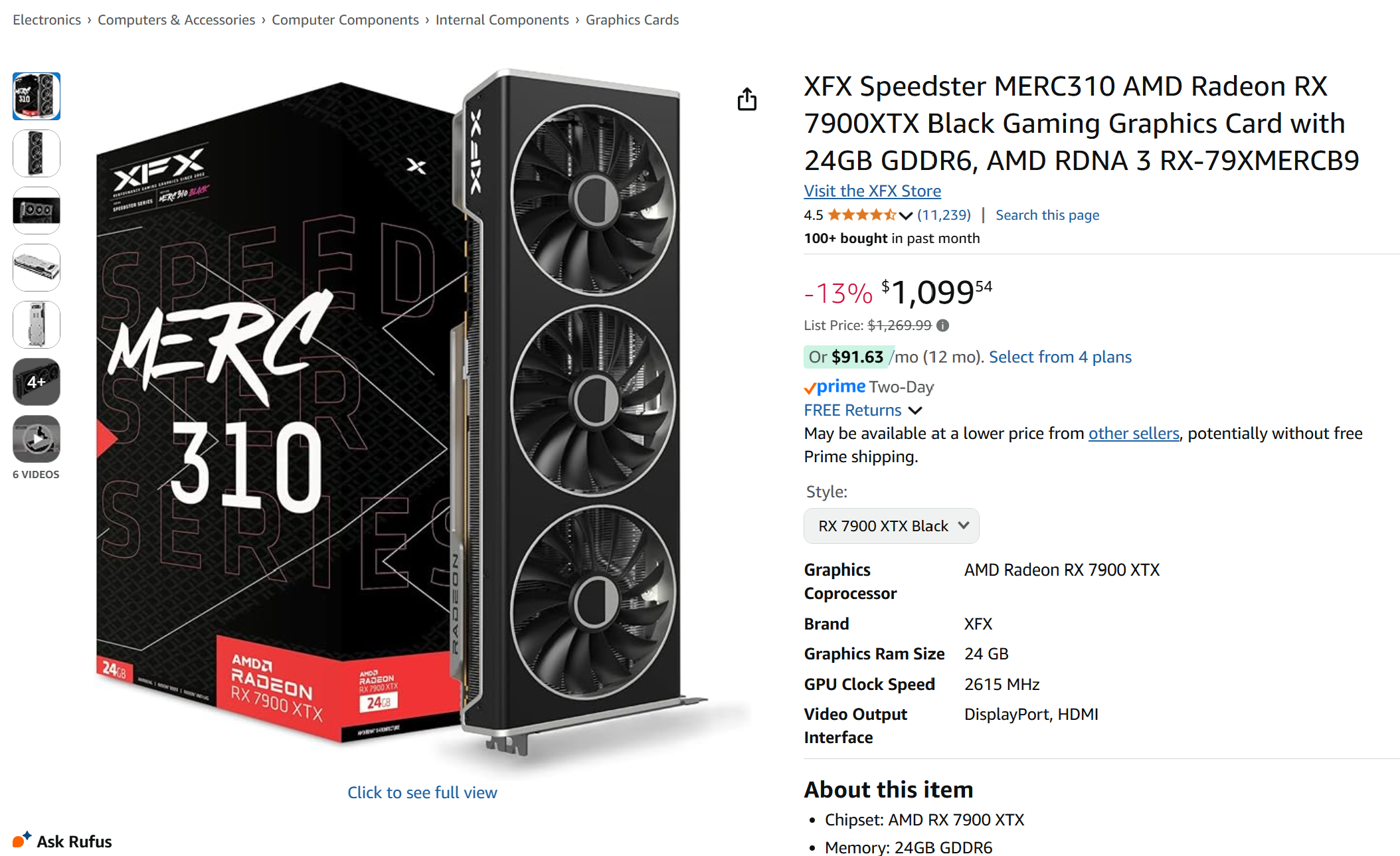
Screenshot of Amazon product page, featuring XFX AMD Radeon RX 7900XTX GPU selling at $1,099.54
I had a retired PC, so I quickly purchased two 7900XTX GPUs:

Two boxes of XFX AMD Radeon RX 7900XTX GPUs
I did my best with cable management:

Two XFX AMD Radeon RX 7900XTX GPUs in an open PC case with PCI power cables connected to them
It was time-consuming, and I tried 😅
Peer-to-Peer PCIe Communication Issues
I ran MNIST and other Tinygrad examples, and they worked fine with one GPU. But with two GPUs, I kept encountering errors like this:
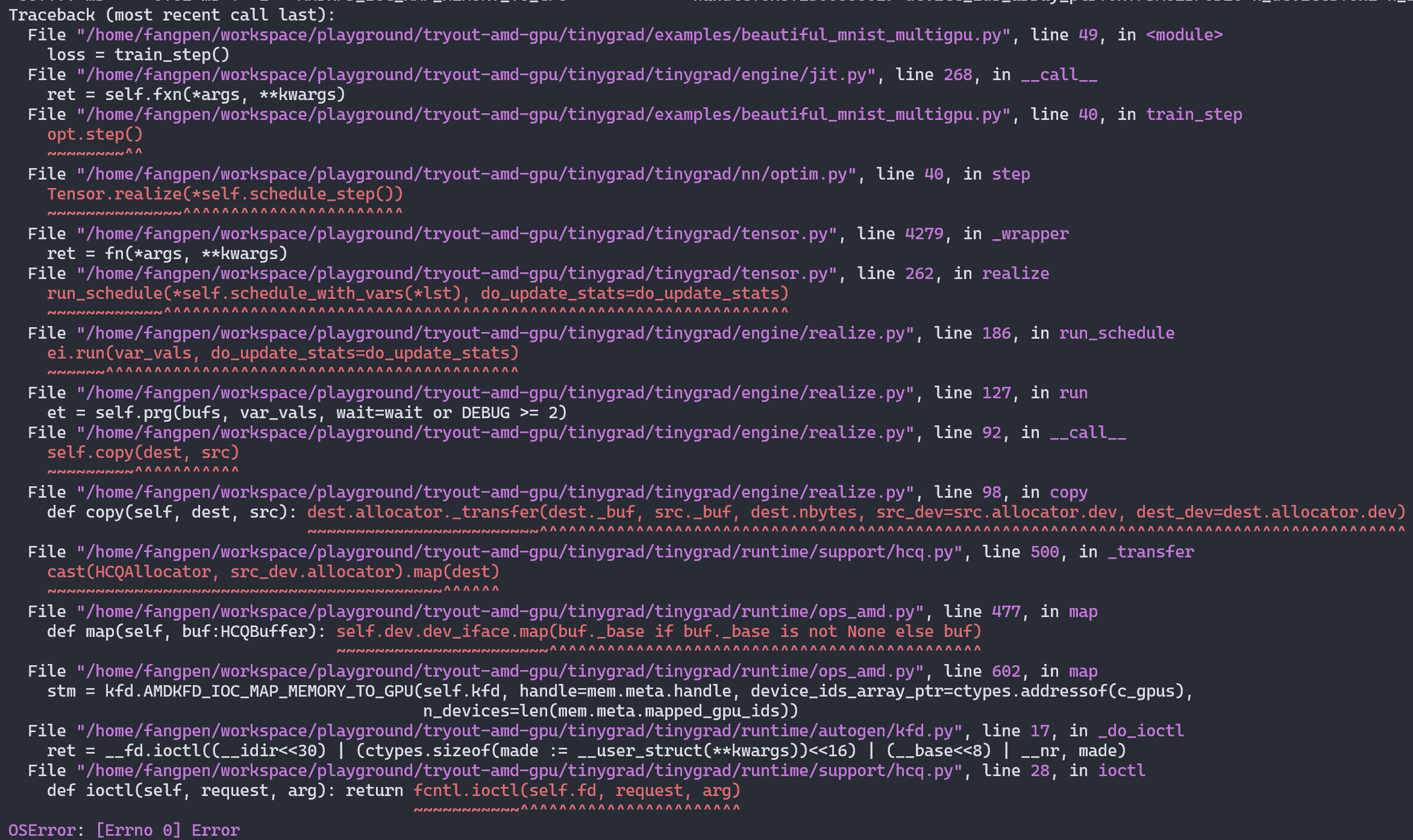
Screenshot of Python raising OSError from a fnctl.ioctl function call when running Tinygrad with the multi-GPUs MNIST example
It turns out the system was trying to transfer data between GPUs using peer-to-peer (P2P) PCIe communication, but this wasn’t available on my setup. If you look at the system log messages, you will see the error message:
Failed to map peer:0000:0c:00.0 mem_domain:4
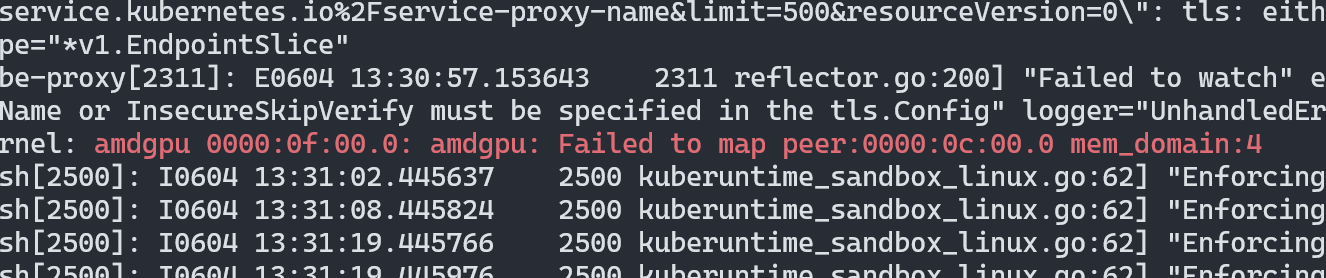
Screenshot from Linux kernel message showing Failed to map peer:0000:0c:00.0 mem_domain:4 error
I discovered a tool rocm-bandwidth-test that benchmarks PCIe communication performance between the CPU and GPUs on the ROCm platform. I tried installing it on NixOS, but it wasn’t in nixpkgs. So, I created a Nix package and submitted a pull request for it. After running the benchmark, I confirmed there was no link between the two GPUs:
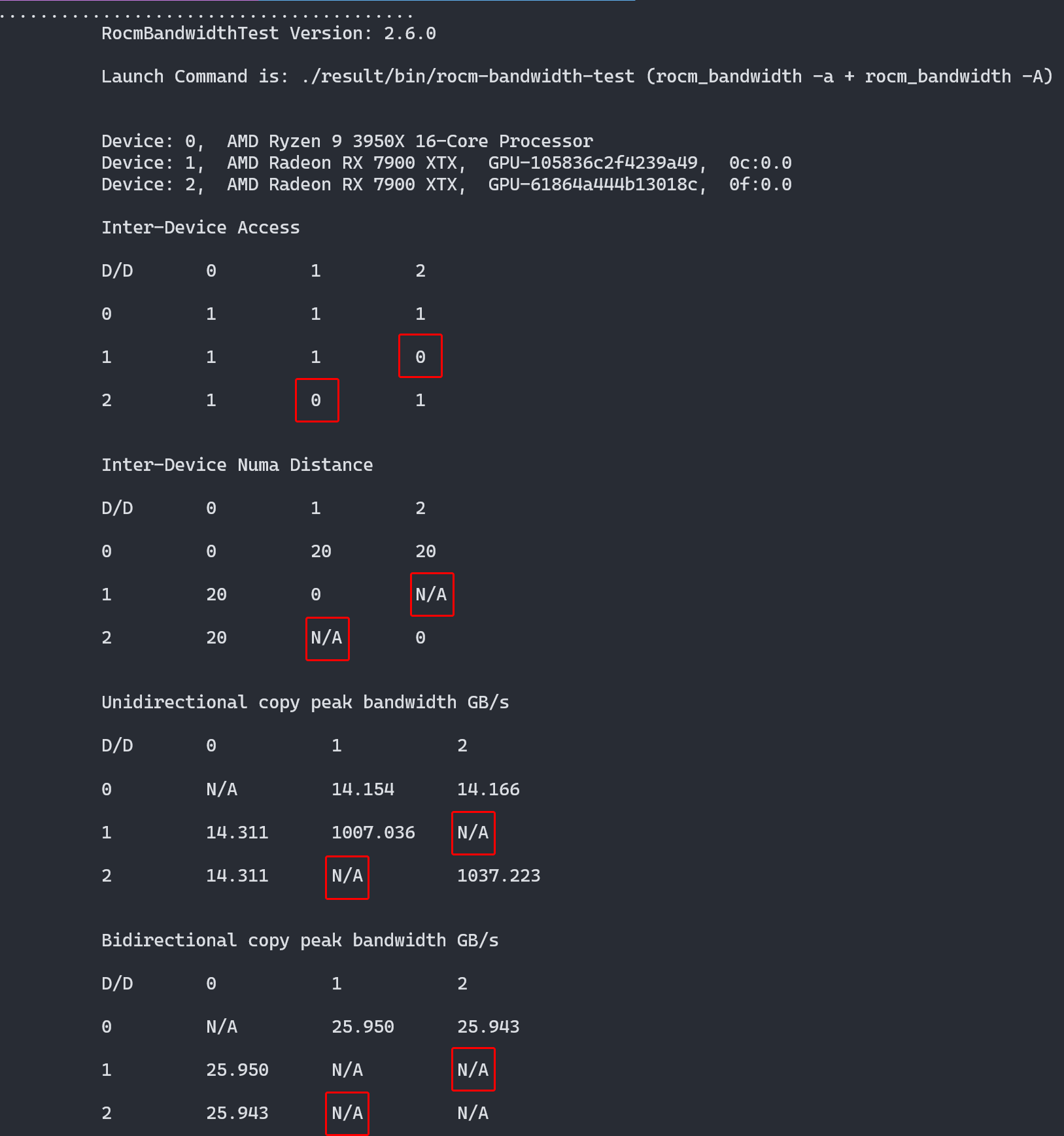
Screenshot of rocm-bandwidth-test's result, shows there's no direct connection between the two GPUs
There’s an amdgpu.pcie_p2p option in the Linux kernel, but it wasn’t available on my PC.
I searched online, but no one seemed to have encountered this issue.
When no documentation exists, even LLMs can’t provide a solution.
Enabling P2P PCIe Communication in the Linux Kernel
I read the Linux kernel config file and learned that the P2P PCIe feature is relatively new.
To enable it, you need to activate DMABUF_MOVE_NOTIFY option while compiling the kernel.
With NixOS, you can configure it like this:
boot.kernelPatches = [
{
name = "enable-hsa-amd-p2p";
patch = null;
extraStructuredConfig = with lib.kernel; {
DMABUF_MOVE_NOTIFY = yes;
HSA_AMD_P2P = yes;
};
}
];
Then rebuild your NixOS system and reboot. After that, running the ROCm PCIe communication benchmark showed data exchanges between the GPUs.
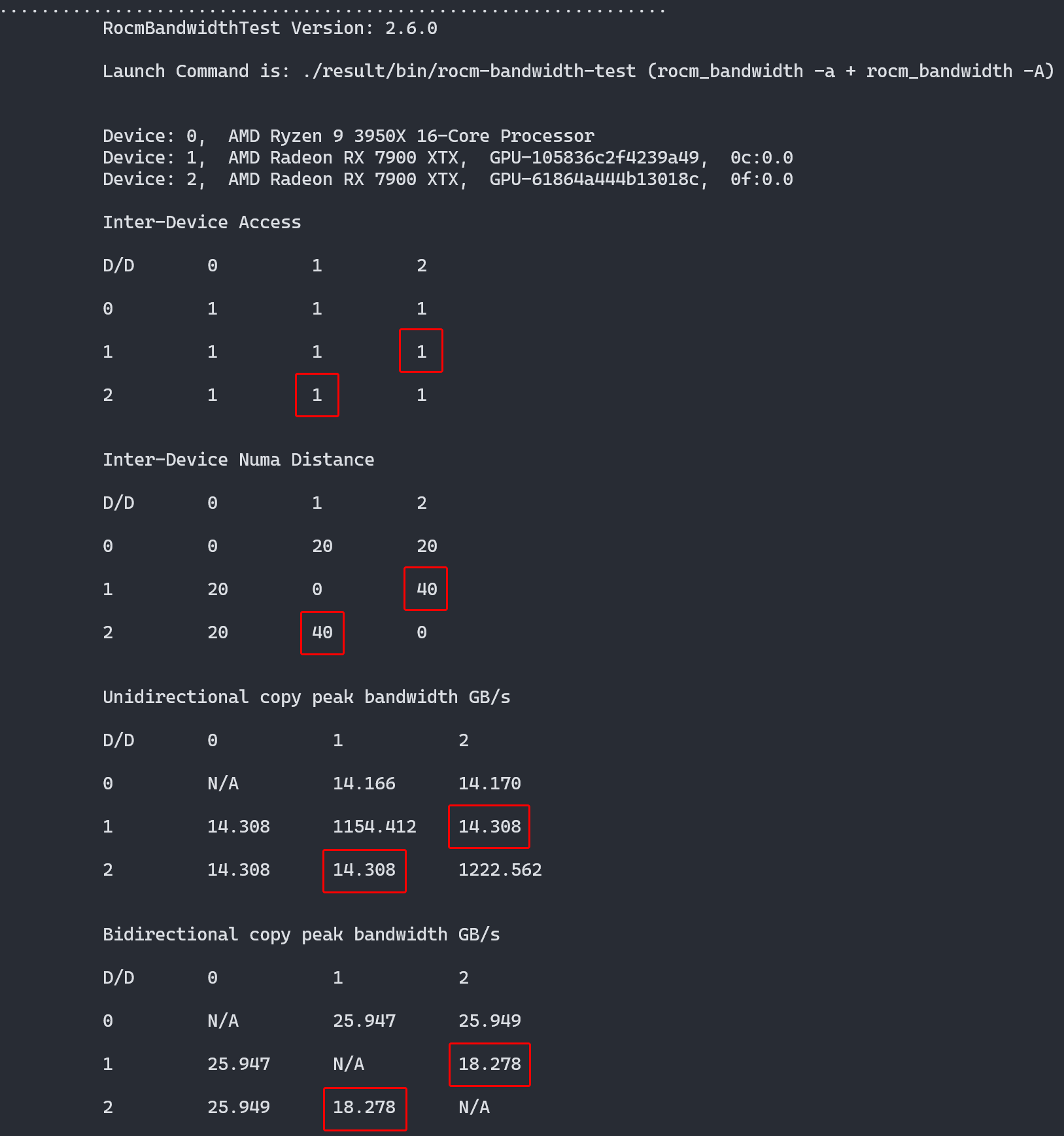
Screenshot of rocm-bandwidth-test's result, shows no direct connection between the two GPUs
The transmission rate was limited due to my motherboard or possibly the AM4 platform, as PCIe bandwidth is shared between the two GPUs:
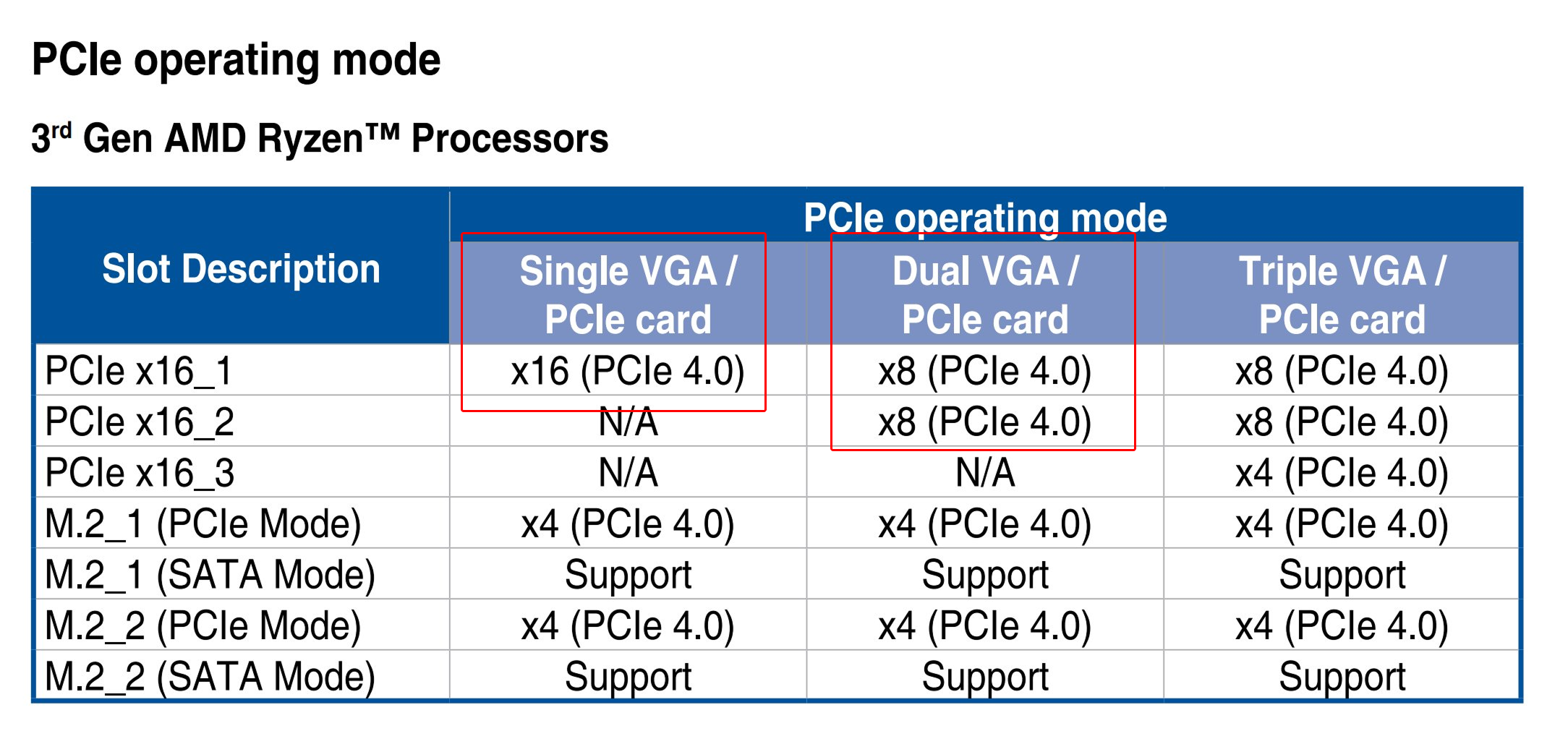
Screenshot from the manual of ASUS ROG X570 Crosshair VIII Hero motherboard shows that with dual VGA setup, each of them have PCIe4x8 vs single VGA has PCIe4x16
To improve PCIe communication speed, I’d likely need to upgrade to a Threadripper platform. But that’s overkill for now. At least it works! To run the multi-GPU MNIST example, use:
IOCTL_PROCESSOR=x86_64 IOCTL=1 AMD=1 python \
examples/beautiful_mnist_multigpu.py
I’m not sure why IOCTL and IOCTL_PROCESSOR are needed, but I ran into other ioctl errors without them.
Now, with two GPUs it’s training at double the performance of a single GPU 🎉:
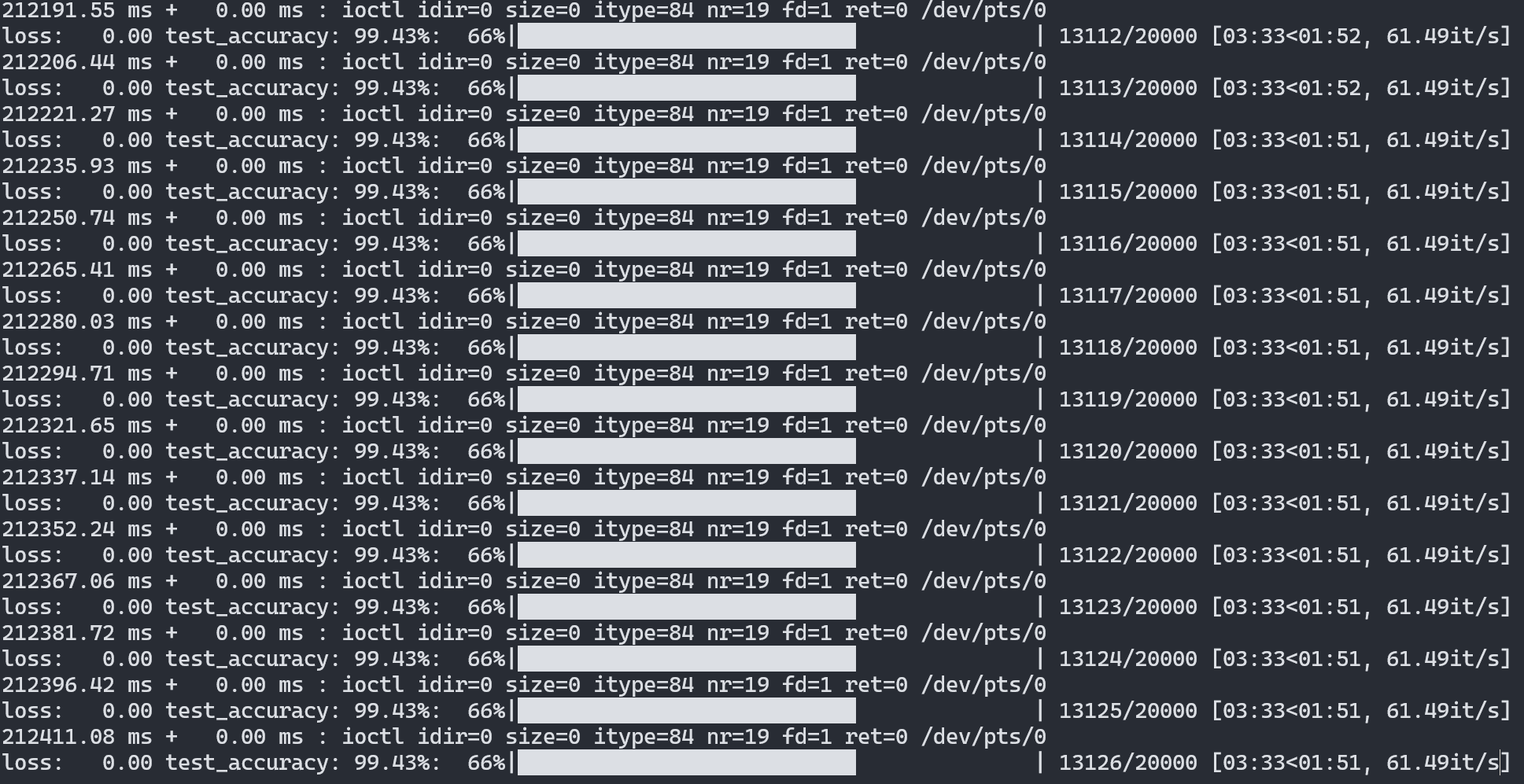
Screenshot of output from Tinygrad's multi-GPU MNIST example on two AMD GPUs running at 61 iterations per second
Compared to the RTX 4090, here’s the performance of Tinygrad’s MNIST example:
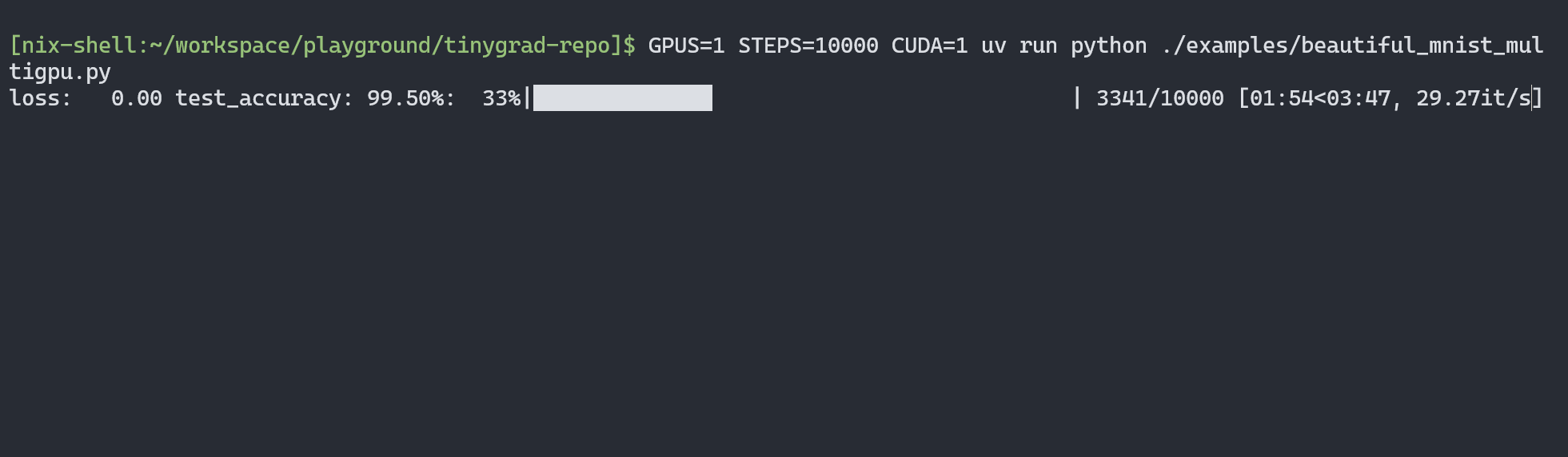
Screenshot of output from Tinygrad's multi-GPU MNIST example on a single 4090 GPU running at 29 iterations per second
Note that this isn’t a scientific benchmark. Tinygrad may have optimization potential or settings to maximize performance on each platform. This is just a rough comparison to gauge the training speed I’m getting. The two PCs also have different CPUs and memory (the one with the AMD GPU has older hardware).
Additionally, the approach I described above uses the amdgpu driver provided in the Linux kernel.
Tinygrad has developed its own custom userspace driver called AM, which they claim is more stable than amdgpu for Tinygrad machine learning workloads.
I’ve only tested it briefly.
That’s another topic to explore later.
Final Thoughts
I’m thrilled to run training with two AMD 7900XTX GPUs at a lower cost in my home office. I can now free up my RTX 4090 and avoid intensive ML tasks disrupting my work. The setup cost me $1,100 × 2 for the GPUs plus a new 1600W power supply for $500, totaling $2,700. I plan to rewrite my ML projects with Tinygrad and run them on my new AMD ML workstation.
I hope AMD gains more popularity in machine learning computing. Otherwise, we’ll be stuck with GPUs priced at $2,000 but selling for $3,600. I appreciate open-source projects like Tinygrad leading the way. As I mentioned in my previous article, the real barrier for enthusiasts like me, who aren’t wealthy, isn’t a PhD degree—it’s computing power. I wrote this article because this information is hard to find online and needs to be accessible so everyone can learn.
That’s it! I may write more articles if I encounter interesting challenges with my dual 7900XTX setup. I hope you find this somewhat interesting and useful 😄