Today, I’m excited to announce that the CakeLens v5 AI-generated video detection model is now open-source! Why open-source, you might ask? Well, the CakeLens project serves multiple purposes for me. (For more background, see my earlier article: I built an AI-gen detection model for videos, here’s what I learned.) The most critical one was to teach myself how to build a machine learning-powered product from end to end, including data collection, labeling, model design, training, and inference. It has already achieved that goal.
Beyond personal learning, I hoped CakeLens could uncover some business value. However, the reality is that most users don’t care much whether the funny videos they see online are AI-generated or not. In an enterprise context, though, detecting AI-generated content is more critical. For example, ID verification services often require users to hold an ID and take a photo or short video. What happens if scammers generate realistic fake photos or videos in the future? What if job candidates alter their face or voice? These issues are already happening.

Screenshot from a LinkedIn post (source) showing a job interview conducted via video call, where the candidate's face has been swapped using AI-generated imagery. This highlights real-world cases of AI-generated content being used for identity fraud in professional settings.
I believe this represents a new market category yet to be fully addressed. CakeLens is my initial step into exploring this space.
While the CakeLens v5 model for detecting AI-generated videos works reasonably well with a limited dataset (77% precision, 74% recall with 50% threshold), its accuracy is still too low for enterprise use cases. I searched for similar open-source models but found none. I guess cool kids are mostly focused on large language models (LLMs) right now. Although this isn’t a flashy moonshot project, I believe open-sourcing CakeLens v5 offers educational value to others. So, here we are!
How Can I Use It?
I have uploaded the model weights to Hugging Face. The model is relatively small, with a size of only 3.25 GB and 270 million parameters. I have also created an open-source library, cakelens-v5, for using the model in your Python projects or as a command-line tool. To use it as a command-line tool, you can run it with uvx like this:
uvx --with torch \
--with torchvision \
--with torchcodec \
--with huggingface-hub \
cakelens-v5 path/to/your/video.mp4
Then you will see the output like this:
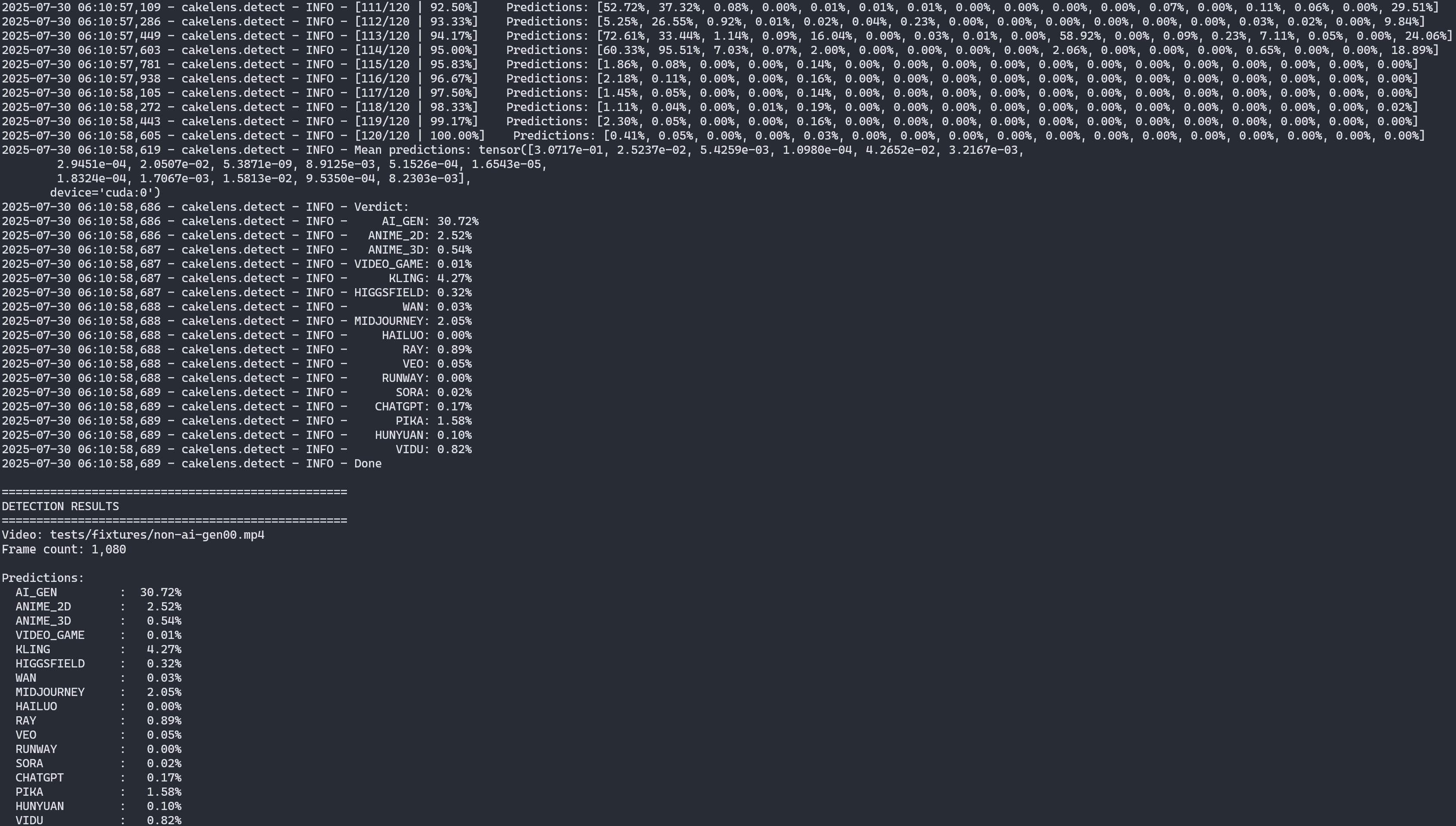
Output of uvx cakelens-v5 command-line tool.
Of course, you can also use it in your Python projects. First, install the library:
pip install cakelens-v5
You also need to install the dependencies:
pip install torch torchvision torchcodec huggingface-hub
# or, if you want to use the model with CUDA:
# pip install torch torchvision torchcodec \
# huggingface-hub \
# --index-url https://download.pytorch.org/whl/cu128
Then you can use it with the following code:
import pathlib
from cakelens.detect import Detector
from cakelens.model import Model
# Create model and load from Hugging Face Hub
model = Model()
# load the model weights from Hugging Face Hub
model.load_from_huggingface_hub()
# or, if you have a local model file:
# model.load_state_dict(torch.load("model.pt")["model_state_dict"])
# Create detector
detector = Detector(
model=model,
batch_size=1,
device="cpu" # or "cuda", "mps", or None for auto-detection
)
# Run detection
video_path = pathlib.Path("video.mp4")
verdict = detector.detect(video_path)
# Access results
print(f"Video: {verdict.video_filepath}")
print(f"Frame count: {verdict.frame_count}")
print("Predictions:")
for i, prob in enumerate(verdict.predictions):
print(f" Label {i}: {prob * 100:.2f}%")
Why v5?
When designing and training this model, I tried many approaches. For instance, I cropped a small window across multiple frames to test performance. I experimented with time-wise CNN layers followed by spatial layers and many other variants. After numerous iterations, I landed on v5, which makes somewhat reliable predictions. Since I went through so many versions to get here, I decided to start with v5 as the first public release—it just sounds cooler! 🤣
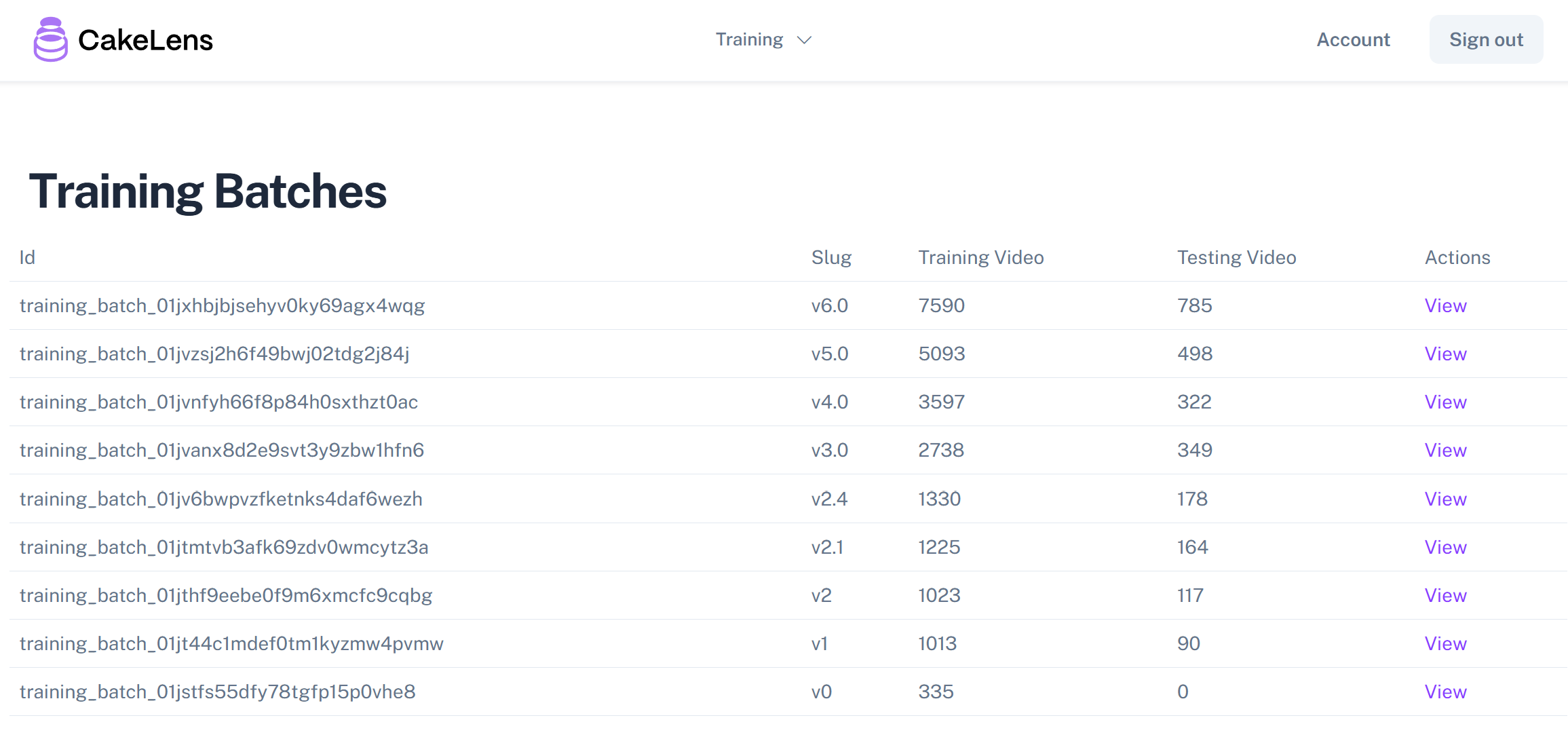
Screenshot of the training batches page of our internal tool showing the dataset size growing across different iterations.
Data Collection
For v5, the dataset consists of 5,093 videos for training and 498 for testing, collected from X and labeled manually one by one. The dataset is randomly split into two groups: 90% for training and 10% for testing. When a post’s author indicates that a video is AI-generated and specifies the model used, I label it accordingly if the information seems reliable. The videos come in various resolutions, such as 1080p, 720p, and others, depending on the original uploaded resolution. Not all videos have high-resolution variants available. I fed different resolution variants into the model to ensure it can detect patterns regardless of image size.
Labels
When designing this model, I wanted to see if it could identify which model was used to generate a video. Therefore, I added labels for each video generation model. Additionally, some videos are anime or video game content. I also wanted to know if the model could distinguish between 2D anime, 3D anime, or video game styles, so I included those labels as well. Despite having more labels than just “AI-generated or not,” the limited dataset size means the model’s predictions for these labels aren’t very accurate yet. Below is the list of labels:
- AI_GEN: Is the video AI-generated or not?
- ANIME_2D: Is the video in 2D anime style?
- ANIME_3D: Is the video in 3D anime style?
- VIDEO_GAME: Does the video look like a video game?
- KLING: Is the video generated by Kling?
- HIGGSFIELD: Is the video generated by Higgsfield?
- WAN: Is the video generated by Wan?
- MIDJOURNEY: Is the video generated using images from Midjourney?
- HAILUO: Is the video generated by Hailuo?
- RAY: Is the video generated by Ray?
- VEO: Is the video generated by Veo?
- RUNWAY: Is the video generated by Runway?
- SORA: Is the video generated by Sora?
- CHATGPT: Is the video generated using images from ChatGPT?
- PIKA: Is the video generated by Pika?
- HUNYUAN: Is the video generated by Hunyuan?
- VIDU: Is the video generated by Vidu?
Of course, new video generation models are always emerging, such as Midjourney Video, which is too new to be included in v5.
The Architecture
The architecture of the model looks like:

Diagram of the CakeLens v3 model architecture. The model processes cropped and resized video frames (9 frames at 512x512 resolution) through an initial convolutional input layer, followed by a series of six space-time convolutional blocks. Each block consists of a spatial convolution (3x3 kernel), a temporal convolution (3x1 kernel), ReLU activations, and instance normalization, with skip connections forming a residual network. The final output passes through a fully connected layer to produce predictions for each label.
As you can see, it’s a simple CNN network with six space-time layers plus one input layer. The input layer primarily reduces computational cost by downsizing the input video. Each space-time layer consists of a spatial layer with CNN kernels that detect features in the spatial domain, followed by a temporal layer that looks for features in the time domain. These layers are connected with skip connections, forming a residual network that makes training more efficient.
For video input, I break the file into framesets, each containing nine video frames at a resolution of 512x512 pixels. Videos larger than this are cropped, while smaller ones are centered and padded with zeros to reach 512x512. This resolution choice reduces computational cost. Additionally, cropping to 512x512 helps eliminate data leakage from elements like TikTok logos, TV channel icons, news banners, or AI-generated watermarks (e.g., “Veo”) that often appear at the edges or corners. I didn’t have time to mask these elements, so cropping minimizes their impact on the model’s decisions.
Interestingly, someone asked why I used a CNN when I shared this project. I hadn’t thought about it initially and didn’t know how to respond. Upon reflection, I chose CNNs because I assumed subtle space-time patterns exist in video frame sequences, and CNN kernels can detect these features across larger ranges in deeper layers. From a product perspective, though, the specific model choice matters less than delivering value and enabling data collection. I can always swap out the model for something better later.
Next Version
I’ve been training the v6 model for a while using a workstation with two AMD 7900XTX GPUs, as mentioned in a previous article. It’s not as fast as an H100 from Modal, so progress is slower. The v6 architecture is largely the same but includes minor adjustments and a larger dataset. Limited computing resources prevent me from experimenting with larger or more complex models for now. I’ll let v6 train for a bit while I shift focus to other projects.
Finally
I hope you find CakeLens v5 somewhat useful or, at the very least, educational. While I can’t dedicate much time to this project right now, it’s now open-source, and I’d love to hear your feedback on how to improve it. Leave a comment below and let me know! Thanks!