Today, I’d like to share my theory about why LLMs cannot replace software engineers, based on my experience and observations. Who am I to talk about this topic, you may ask. Well, not much, except that I have spent more than two decades of my life programming, almost every single day, long before GPT was a thing. You can check my GitHub profile, but it only captures one decade+ (from when git was a thing), and those are just GitHub repos not including all proprietary repos I have worked on.

More than a decade of GitHub contributions on my public profile. This is only what GitHub can see (public + any private contributions I opted to show), not the proprietary repos I’ve worked in.
These are all organic commits. I never commit a single line of code just to make my GitHub profile look green, because that’s stupid. Before LLMs, I wrote almost all my code keystroke by keystroke. Sounds crazy, right? 🤣
Yep, that’s how things used to be. And it can last for so long only because I truely enjoy programming. I’ve built countless software projects: backend, frontend, mobile, data pipelines, browser extensions, infrastructure as code, and even trained AI models from scratch, and so on. After using LLMs to speed up coding, I have to say: if you use them the right way, they can make you many times faster. But it’s not all sunshine and rainbows, if you rely on them too much, programming becomes painful, and it chips away at your ability to think like an engineer from first principles. I did some soul-searching and found that I still enjoy programming, so I intentionally handwrite code from time to time to keep the muscle strong.
Like many of my fellow software engineers, I used to panic a bit when I saw machines spitting out code like crazy fast. Are my experiences from the past two decades all in vain? But the truth is, the more I learn about LLMs, the more I use them, the more I realize it is not like many claim, that they could replace software engineers in 12 months. I didn’t buy into the hype, but at the same time, I don’t feel desperate. Instead, I feel cautiously optimistic about the future of software engineering.
Because, simply put: no. Despite many tech companies committing collective suicide by drinking the Kool-Aid, LLMs are not going to replace software engineers. Most people confuse the idea of coding with software engineering. LLMs surely have a huge impact on the software industry: they speed up many things greatly, but like any tool, there is a trade-off. Now the cost of making sloppy software goes down almost to zero, but that does not mean software engineers will disappear. Let’s see why I think it is this way.
Entropy, LLMs cannot escape the information density of the software spec
One of the main reasons why LLMs cannot replace software engineers is the limitation imposed by the information density of the software spec, i.e., Shannon entropy. Software development is a process of discovering the requirements and removing the uncertainties. Usually, we start with a rough idea about the system, for example, say we want to build a login page. You can tell the LLM
hey, build me a login page
The concept of a login page is a well‑known idea to LLMs because there are countless login pages implemented in various programming languages. However, when you tell an LLM to build such a page, the model does not have any context about the details of your specific login page. Therefore, for the system you are building, there is a high level of uncertainty. An LLM will generate the most likely code based on statistical norms embedded in its weights from the training data. With a non‑zero temperature (the level of randomness of picking the next token from the list of token candidates) plus the internal statistical model, there is a distribution of plausible outcomes.

A spectrum of plausible login pages when the spec is just "build me a login page". Little entropy (information) provided → high uncertainty about the outcome.
At this point, you have offered little entropy (information) about the system requirements. Because of the lack of information, there is high uncertainty about the system. You are basically rolling a die. Due to the similarity between using LLMs to generate code and gambling, some people on X even came up with a funny comparison to gambling:
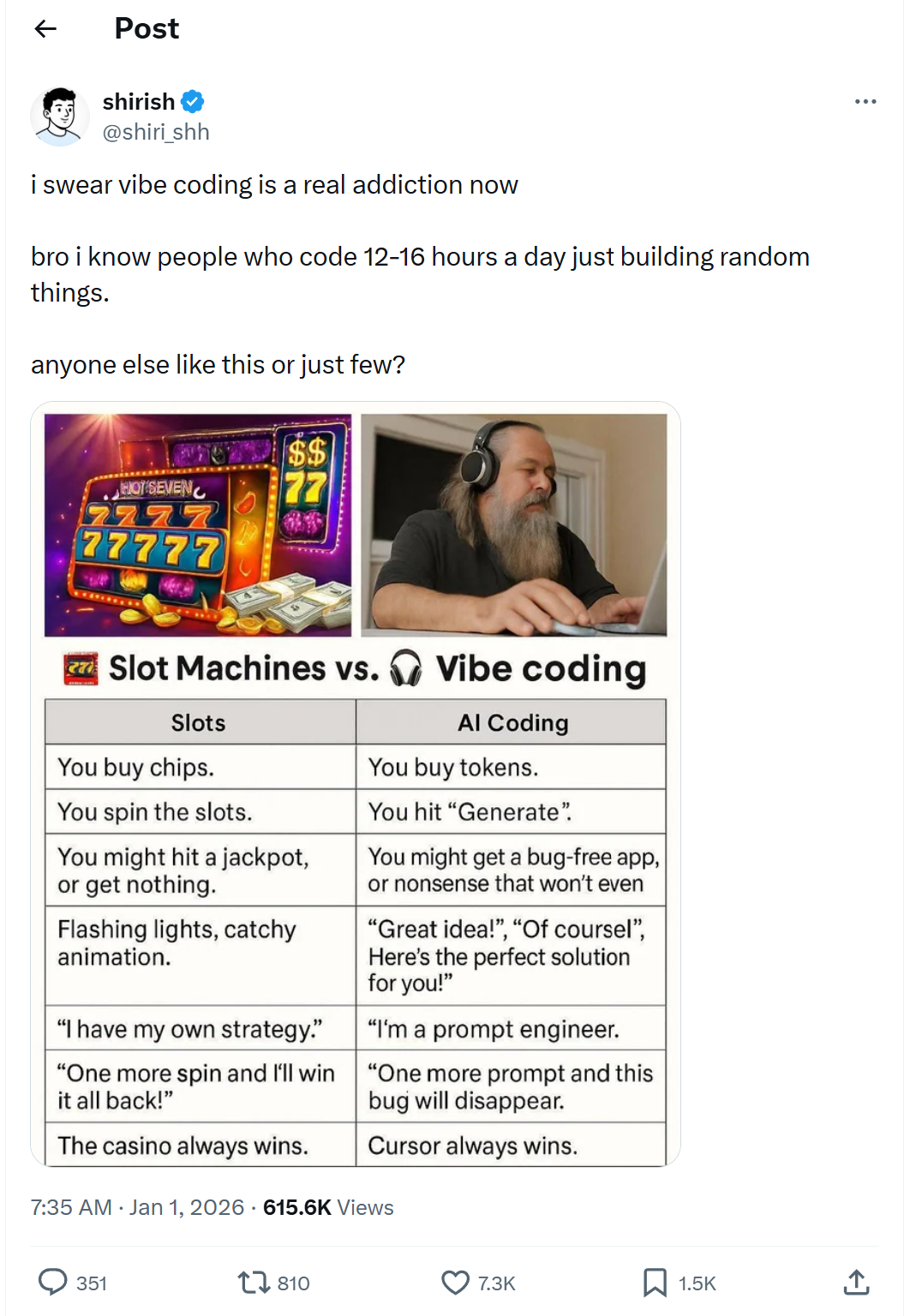
A meme comparing vibe coding with LLMs to gambling/slot machines. Source: original post on X.
The end result may not be the best login page in the world, but it will probably come with very basic stuff and it might just work. If you do not like the look of the login page, you can then supply more entropy about the software spec. Say, you want the login button to be blue. Now your login page spec goes from just a login page to
a login page with a blue login button
By trading in more entropy (information), the uncertainty of the system is reduced. But here comes yet another problem: what kind of blue? There are so many shades of blue; it’s a big range. You can either roll the dice multiple times, or you can put it in the prompt directly, saying you want a particular type of blue, like Baby Blue, for example. Whether you are rolling the dice multiple times and pick one or supplying the details in the prompt directly, it is essentially the same thing: you are supplying more entropy (information) to the system spec and reducing uncertainty.

Adding one constraint ("the login button is blue") injects more entropy into the spec and narrows the output distribution, uncertainty decreases, but doesn't disappear (there are still many "blues").
After some iterations, now you have a beautiful login page with a blue button that meets your taste. As a person who cares about security, you might want a two‑factor authentication feature after the user inputs their username and password as an extra layer of defense. Now, your software spec has become
a login page with a Baby Blue login button; after user login we need to prompt for two-factor authentication
Well, once again, there are many two‑factor authentication mechanisms to choose from. It could be hardware-based like YubiKey, biometric info like fingerprints, facial recognition, SMS, or email one-time passwords. There are so many options. Which one would you like the LLM to build?

When the requirements are more specific (e.g. a specific blue + a two‑factor auth flow), more entropy is provided in the spec and a smaller space of plausible implementations is imposed.
You see, this is a very simplified version of software development. We can play this game forever: keep adding new requirements and ask the LLM to generate code for us. But here comes another question: why blue, but not yellow? And if we are going to implement email one‑time passwords, why not get rid of the username and password, relying only on emailing the code? In fact, many software systems do that. For example, Slack has chosen a passwordless approach as its authentication method. The different choices present different paths you can take in building the system. If there are parallel universes, there could be multiple versions of you making different decisions about system design. If we draw the diagram again for each of them over time, you will see something like this:

This is not an exhaustive map of every possible login page, it's a mental model under a "parallel universes" thought experiment. As you add requirements and make design choices, the "spec" can branch into a tree, representing the many plausible paths you could have taken.
All possibilities for building a system could span a tree structure. The trend is very obvious: over time, with more entropy supplied, uncertainty goes down.
The system spec data density grows exponentially with the software usage and the value it provides
You may ask
Why does this have anything to do with LLMs not being able to replace software engineers?
First of all, while LLMs are very good at generating code based on the instructions you give them, they are not good at discovering and validating the spec by themselves in the real world. You still need someone (or some accountable process) to collect feedback, get hands-on with the system, arbitrate trade‑offs, and feed more details into the software spec to reduce uncertainty.
And the more details in the software spec, the more information you need to provide to make it more certain. The density of information about the software requirements is something you cannot escape with LLMs. Shannon showed us (via information theory) that there is a limit to lossless data compression: you can’t, in general, represent arbitrary information with fewer bits than its inherent information content. In practice we often “compress” specs by leaning on conventions and shared references (framework defaults, “make it like Stripe checkout,” existing libraries, existing test suites). But the moment you deviate from those well‑known paths, the missing information has to be supplied somewhere (prompt, tests, code, or human decisions). No matter how hard you prompt, you still need to find a way to convey the idea of your system, either in plain English, tests, or in programming language.
Certainly, LLMs can translate your English prompt into code, empowering many people who do not know how to code. Now they can at least build something. For people who already know how to program, it also saves a tremendous amount of time from mechanical work. But regardless, there is no way to consistently convey an idea with less information than is theoretically necessary to disambiguate it. In other words, LLMs act as an amplifier in coding and drafting, while finding, negotiating, and defining clear requirements remains a hard, human‑in‑the‑loop challenge.
I do not care about the login page, as long as it works, I am fine with it
I heard you yelling at me. Well, the login page is just an overly simplified example to help the reader understand the concept of software development and the relationship with information entropy. Sure, if you do not care about the actual output of the system, then indeed LLMs can do a great job, because they can generate something that looks like it works the way you want. In fact, not all subsystems in a software project are equally important. Even if a page looks ugly, the code is a mess, but it works, who cares?
That kind of statement usually comes from people who vibe‑coded side projects which have nothing to lose. Based on my own experience, as the usage of a software system grows and the business value it produces increases, so do the requirements. And the growth of requirements does not come in a linear fashion; it usually grows exponentially, or at least super‑linearly.

As usage (and the business value on top of it) increases, the amount of system spec/requirements tends to grow non‑linearly, often super-linear or exponential in practice.
Say you have a website that serves one hundred people per day and makes no money, versus a website serving 10 million users per day across the globe with a business that makes big money on top of it, the requirements would be completely different. For the website with very few users, nobody really cares if the website goes down, certainly nobody cares that much about the color of your login buttons. But for a 10M DAU (daily active users) website, I can easily name many obvious requirements:
- Security requirements: ensure user data will not leak, because now it has real-life impact
- Performance requirements: with high load, you need to serve that many people efficiently
- Reliability requirements: SLAs with customers, uptime requirements, etc.
- Compliance requirements: GDPR, different local laws, data retention requirements, etc.
- Requirements from legacy code: given that the website has grown from nothing to 10M, there must be legacy code some users still depend on; you still need to keep it around for some time
- …
The list can go on and on. Just the sheer amount of information in those requirements is tremendous. Even if there were a perfect LLM that could translate your software spec into code flawlessly, you would still need to provide those specs to the LLM. So the bottleneck doesn’t disappear; it shifts. If the hard part is specifying and verifying behavior under real‑world constraints, then “replacing engineers” would require replacing that spec/verification work too, not just typing code faster. This is why I think it is unrealistic for LLMs (as we use them today) to replace software engineers: that’s not what they are designed for.
There are different types of people claiming LLMs can replace software engineers. One type is people who have a stake in LLM model companies, they need a story to keep the VC money flowing. Another type is people who have software with nothing to lose, of course LLMs could work great in that case:

The low‑usage, low‑stakes "nothing to lose" zone is where LLMs shine in terms of generating low-quality software quickly. But once the software has something to lose, the sheer amount of requirements can make LLMs less effective, because the entropy of the requirements might be as big as writing the code yourself.
Functional requirements are easy, non‑functional requirements are the real challenges
So far, we have been talking about the software spec. As you see in our login page example, we only use functional requirements as examples, because they are very easy to define and verify. However, as you saw when we discussed potential requirements for a large-scale website, most of these requirements are not even functional. There is a joke surfacing around X capturing the irony perfectly:
To let AI build a secure system, you should tell AI:
Build a secure system, make no mistake
Do not forget the important part “make no mistake”
This prompt carries almost no entropy at all. A requirement like this is extremely hard to define in simple terms, because it is not a single piece of code that you can magically generate and the whole system would be secure because of that. The security of a system relies on whether every single line of code is doing the right thing, while taking all possible attack vectors into consideration. It even includes all the third‑party libraries, your upstream vendors, and how they handle security from their ends. And of course, there is no unbreakable system, you also need to consider the value of the compromised system and the potential cost for the attackers.
A simple prompt like that implies a full inspection of every single line of code on a potential attack surface. And there is no easy way to verify whether you are doing it right or wrong. There is also an implication of taking user mistakes into consideration. System requirements such as performance share similar challenges, they are hard to define and verify. Also, while functional requirements are usually only impacting a local subsystem, non‑functional requirements usually have a global impact on the whole system. For example, you may have multiple subsystems running at the same time, and eventually there is a final task that collects the result and reports it to the user. The actual performance of the whole system is defined by the slowest one:

A "shortest barrel stave" view of system performance: like Liebig's barrel, the overall capacity is limited by the weakest part, not the average. One slow or fragile subsystem can cap the whole system (same "weakest link" idea as Liebig's law of the minimum).
Security and compliance are similar: if you have any weakness in the system, or anything that violates compliance, the end result is the same: a breach or a compliance violation. It does not matter how good your other parts are doing.
Now you see: given how hard and wide-ranging the non‑functional spec’s impact on a system is, the required entropy to define such a system is much bigger than for functional requirements. We will talk more about this in the hidden context and software verification sections.

Software requirements are like an iceberg: the visible functional spec above the waterline is only the tip, while the much larger mass of non‑functional constraints (security, reliability, compliance, operability, etc.) sits hidden below the surface and dominates the true complexity.
Programming code is also spec, and reading code is harder than writing code
Usually, in a healthy software system you will have high level human readable language, like design docs, potentially plus BDD (behavior‑driven development) / e2e (end‑to‑end) tests to define how the system should work from a high level. Then, software engineers will write code based on the system spec. People forget, we came all the way from machine code to high-level programming languages. It’s already very high-level compared to what it used to be. The code itself is also spec, it tells the machine how to behave. So the programming code itself also carries a big portion of the entropy about how the system should behave, in detail of course. It might be something like 10% / 90% to 20% / 80%.

A pyramid view of software: a relatively small, high‑level system spec at the top, and a much larger volume of detailed code at the bottom that implements and refines that spec.
LLMs indeed changed the game. Now, instead of writing the 80% of code yourself, it is possible that you only write the top 10% ~ 20% of the system spec, and let LLMs generate the code for you.

The same pyramid, but with the bottom filled by AI‑generated code: the high‑level spec is still small, yet a large volume of detailed code appears underneath it. Without careful review, that code is annotated with question marks.
This feels like magic, because now it seems like it saves you 80% of the work of writing code yourself. However, the problem is, the code is generated as the most likely arrangement of tokens based on the given prompt and context. It is an average of what the code might look like. Before someone reviews the code and verifies the intent of the generated code, whether it really meets all the requirements defined in the spec, and whether there are any bugs in the code, it is still just plausible code based on the spec.

Left: low-quality image of the CEO of NVIDIA. Right: AI upscaling result of DLSS 5, obviously not the CEO of NVIDIA. It's a joke, obviously 😅 Originally from this X post; I modified it slightly so the point is clear. AI can resize or enhance images, but when the original data is not there, it can only guess and may invent details that do not exist, much like generating a large amount of source code from a small portion of spec.
If your software has nothing to lose (no users, no customers), most vibe coders would just stop here. Because it seems like it is doing what they want it to do. In that case, they do not care about quality. We just mentioned in the previous section, when the usage and business value of the software system grows, so do the requirements. If the vibe coder is lucky enough and their software is no longer a toy but a business, they face a problem, they either take it seriously and fix the critical problems, like performance, security and compliance, or risk losing everything they have just gained. Now the software has something to lose. You are forced to add more software requirements into the system spec, be it performance, security or anything else.
If you just vibe‑coded the system, have zero clue what the code looks like, but you do have the spec, one obvious idea is to add all your requirements into the spec and let the LLM generate the code again for you.

An extreme case: a huge, detailed system spec sitting on top of a tiny amount of code. When the entropy in the spec vastly exceeds what the code actually covers, it might be much easier to just write your software spec in the code as using English to define such accurate details would be impractical.
Here is the problem, now you have a super huge system spec carrying all the entropy. English is not an accurate language. Describing roughly how a system should work might be good enough. But describing how software should work from the high level down to tiny details would be a nightmare. In that case, letting code carry the implementation details, i.e., the entropy of the software spec, is a better idea.
Why trading code generation speed with more code reviews is a bad deal
LLMs generate code extremely fast; it almost feels instantaneous compared to humans. But now we know that code generated purely with LLMs, without review, is just a plausible implementation of your spec. We still need to review the code. Engineering is all about trade-offs. Using LLMs or not, reviewing code or not, each comes with its own pros and cons. Now, let’s see what’s the deal we are making here.
As mentioned previously, most people don’t realize that reading code is actually harder than writing it. But how hard is it? This is my personal experience (it’s very case-by-case), but in general, I would grade the difficulty of programming activities as:
| Activity | Difficulty (relative units) |
|---|---|
| Thinking | 6 |
| Writing | 3 |
| Reading other’s code | 10 |
| Naming | 999 |
Usually, thinking is the most challenging part other than reading other people’s code. Once you know how it should work, writing it down is the easy part. Of course, you may need to check the library, syntax and some details about the programming language. Depending on how familiar you are with it, sometimes it can be slower or faster. But with LLMs, you save a great amount of time on mechanical work. Researching syntax, reading library docs; many of those can now be combined into a single prompt.
Reviewing other people’s code is usually hard because, as mentioned previously, you are guessing the author’s intention; it’s puzzle-like by nature. Even for your own code, after some time, you can forget the details; it will be hard for you as well. Of course, not all code is complex, but even a one-line change can have hidden context behind it. We will talk about the hidden context later, you will see why it’s so hard.
With LLMs, I would say the difficulty of writing goes down to almost zero. I would put it as just 1 here:
| Activity | Difficulty (relative units) |
|---|---|
| Thinking | 6 |
| Writing | 3 → 1 |
| Reading other’s code | 10 |
| Naming | 999 |
The productivity has indeed been improved greatly for writing, from 3 to 1. However, if you are not happy with the gain, there’s still something you can do. You can delegate part of the “thinking” to LLM. For example, you want to achieve something, but you don’t know what to do; you can ask an LLM to make a decision for you. In that way, you’ve saved time from thinking, right?
Well, yes, but no. As you can see, the difficulty of thinking goes down, let’s say to 1. But because it’s not your intention, you don’t know why the LLM is doing that, so you need to review it as like you would for other’s code. Depending on the code quality and volume of generated code, the reviewing difficulty could go up even further, say 20 instead of 10.
| Activity | Difficulty (relative units) |
|---|---|
| Thinking | 6 → 1 |
| Writing | 3 → 1 |
| Reading other’s bad code | 10 → 20 |
| Naming | 999 |
If you are in a team, your co-workers need to review it, that would multiply the cost on reviewing slop code generated by AI. It’s insane when you think about it: you pay a lower cost to trade for something with a much higher cost. It’s a huge net loss. Therefore, I would say, if you care about software quality, outsourcing thinking to LLM is a bad idea.
LLM is not doing great outside of its comfort zone
The term comfort zone is used to describe the area people feel comfortable in, but I think it’s perfect for describing LLMs as well. In the previous diagrams we have shown, the well‑known paths of approaches / algorithms / code patterns available in great amounts in the training data from mostly open‑source projects are exactly the comfort zone of LLMs.

The "comfort zone" of an LLM is the set of patterns it has seen a lot of during training (common frameworks, common algorithms, common app shapes). Inside that zone, outputs are usually solid; outside it, uncertainty spikes and the model is more likely to guess or hallucinate.
LLMs can do extremely well in their comfort zone, but not outside of it, simply because the whole system is built to recognize patterns and predict based on them. For all the software, algorithms, building blocks with good amounts and great quality in LLM training data, I call them commodity software.
However, if there is any requirement outside of well‑known patterns, LLM performance degrades greatly. In simpler terms, LLMs are not creative. More often than not, LLMs make things up if asked to do things outside of their comfort zone, i.e., hallucination.
For example, as in the login page example we just mentioned above. Most login pages all look mostly the same, but what if we want to do something really odd and barely seen out there? Like:
Hey, build me a login page and only grant access to the user if they can perform the Moonwalk perfectly on camera
I have not really tried, but my gut tells me it might actually be able to make one. But the reason is not because the LLM is creative and comes up with algorithms to detect human movement on camera, it would more likely be because there are algorithms for detecting human movements in some open‑source projects it has read before. It can either use those libraries in the code it generates, or write down the algorithm it memorized with twists in the target language and taking the context into account. Using existing building blocks to create something new, that is what software engineers do on a daily basis. LLMs can certainly do similar things, and it makes people feel they are super smart or even creative, but under the hood, they are chaining the patterns seen in the training data. In the case of using the moonwalk dance move as a way to log in, whether the moonwalk is accurate or not can be output as a simple value. Somewhere in the weights, it has seen the pattern that you can chain output from one system and pipe it to another system, so it applies that rule.
Say if we live in a universe where all the body motion research and the corresponding code do not exist, and you give an LLM such a prompt, it will not know how to do that. Or, even if it tries, there is little chance the system could work.
Hidden context
Yet another reason LLMs cannot replace software engineers is because of hidden context. I have been learning Japanese lately, and I realized Japanese is a very context‑dependent language. People get used to communicating with hidden context that is obvious in that environment. Here is an example.
好き
It means “like” in Japanese. If this is an anime scene, a male student saying it to a female student, it is obvious the male student is saying to the female student that “I like you”. If you put just “好き” into Google Translate, despite translation technology being really advanced nowadays (thanks to transformer models), it still does not understand the implied “I like you” part. It can only guess the most likely meaning of “好き” based on statistics from its training data.
As we mentioned in the first section, we discussed how important contributing entropy and reducing uncertainty are to a software project. When a software engineer writes a few lines of code, there could be hundreds of considerations in their mind when writing them. It could be anything like:
- Performance considerations
- Security considerations
- Compliance considerations
- Legacy code considerations
- Workarounds for third‑party bugs …
- …
So on and so forth. Most of the time, there will be nothing mentioned in the code about those intentions. If you are lucky, the engineer who takes good practice seriously may leave a comment explaining why these lines are here. But more often than not, this context stays in the author’s brain.

Another iceberg: the prompt and the code you can see are just the "visible context". The bulk of engineering intent is "hidden context" (trade-offs, constraints, historical decisions, production failures, tribal knowledge) that rarely makes it into the code or the prompt.
It is not because software engineers are lazy (well, sometimes we are 😅), but rather because the entropy of those hidden contexts would be tremendous if we had to write all of them down in detail. The code is just the artifact of the thought process. When LLMs are trained based on that code, the LLM has no idea about these hidden contexts. For example, why are we using syscall A instead of syscall B here? There could be a reason, maybe syscall A performs better in the first situation and syscall B performs better in the second situation? Or, maybe we need to support legacy Linux kernel here, so that despite it’s a bit slower, we need to use syscall A instead of B? Skilled and experienced software engineers usually bring far more considerations to writing the same line of code than junior software engineers. Sometimes you would be surprised by how many considerations are behind a simple few lines of code.

"Hidden context" (constraints, trade-offs, historical incidents, performance profiles, production realities) drives the choice between multiple plausible artifacts (code A/B/C). But that context is usually invisible to future readers, and therefore invisible to LLMs trained only on the code.
When you prompt an LLM:
Write me performant software, MAKE NO MISTAKE!
It is not going to work, as mentioned previously, this is outside of the comfort zone of LLM models. Not because there is zero data in the world (there are benchmarks, perf reports, CVEs, postmortems, and private incident history), but because the relevant context is rarely captured in the artifacts the model sees at generation time, and often isn’t written down at all. How do you know these lines of code are here, or why the order of lines matters for performance reasons if it is not explicitly stated? This is why I say reading code is many times harder than writing code, because you can only guess about the author’s intention if they do not write it down.
Disorderness compounds over time
Yet another reason is, in a system with lots of low-cost code generation (LLM or not), the entropy (disorderness) tends to grow over time unless you spend deliberate effort to remove it. The entropy here means disorderness rather than the information amount as we mentioned before, it is from thermodynamics:
Any isolated system, entropy (disorderness) will only grow over time (i.e., the second law of thermodynamics)
Because I have used the term entropy too many times, to make this easier to read, I will use disorderness instead moving forward. This is only an analogy (software projects are not isolated thermodynamic systems), but it matches a familiar engineering reality: if you can produce code faster than you can review, delete, and simplify it, noise accumulates.
What I mean is: for an LLM to generate code that works (or is more likely to work), it tends to copy code that it has no idea what it is for. For example, recently I cleaned up some useless lines added by an LLM:
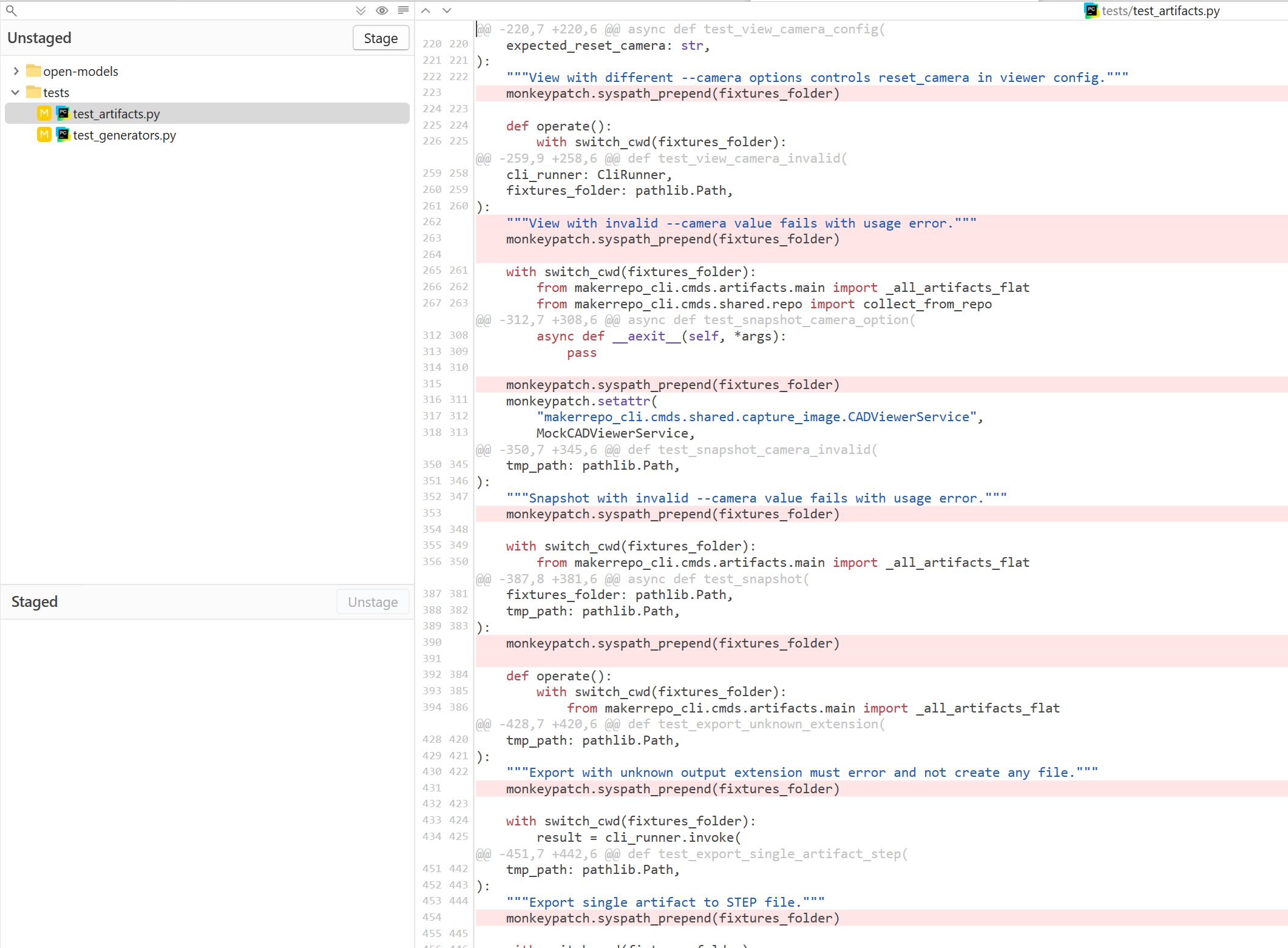
A real diff from Fork: removing unnecessary defensive or cargo-cult lines that an LLM sprinkled throughout the codebase. This kind of cleanup work is "anti-entropy", restoring signal by deleting noise.
Not only that, if you ever use LLMs to generate code and you have coding experience without using LLMs, you will notice that the LLM models act very defensively when generating code. They will always try to catch any exception, and when importing a library they will fall back to the situation if the library does not exist. These lines of useless code look harmless, but they are a kind of disorderness added by LLMs. They not only make the code potentially run slower, they also make the code much harder to read. It is purely adding noise to the signal. Over time, more and more noise will be added to the code base, the noise‑to‑signal ratio will be higher than ever. Not only will it consume more tokens to process, at some point the LLM itself will lose focus.
It is funny: even in 2026, there are still people using lines of code as a measurement of productivity. I saw people brag about tens of thousands of lines of code an LLM generated, as if we are in a competition to generate as many lines of code as possible. Unfortunately, for people without software engineering experience, it seems like a logical idea, as software engineers produce code, the more code the better, right? No, that is totally wrong. Code is liability: the more lines your codebase has, the more likely it is to have bugs. And more code means readers will need to spend more time reading through nonsense; even your LLM will spend more tokens reading it.
You know what is harder than generating code? Removing code without breaking the system or reducing the functionalities. Because it requires complete understanding of how the code works, why the line is not needed, or whether there is a better, simpler flow to achieve the same thing. So far, I have never seen an LLM that is good at removing code without breaking things, because once again, that is not what the system is designed for.
Without removing the disorderness and noise from the code, very soon, you will realize that it gets harder and harder to prompt the LLM to modify software without breaking it. Most people out there vibe coding their pet projects, and their pet projects do not survive long or become complex enough to hit that wall. In other words, anti‑entropy needs to be introduced periodically to keep the code base’s noise‑to‑signal ratio below a certain level. We usually call it refactoring. LLMs are good at mimicking, but they are not good at understanding, so it will not be helpful if you let them do it for you. Because this task requires understanding of the system, fortunately or unfortunately, you will still need an experienced software engineer to help you do so.
Software verification is still challenging, and becoming more important than ever
We have already talked about this a lot. If your software has nothing to lose, you probably do not care about any of this. But say you have something to lose, then software verification is going to be the really challenging part for you, even with LLMs. Usually, to ensure the system works as expected, we will write BDD tests, end‑to‑end tests, acceptance tests and other tests to have a way to verify the system automatically. In a healthy software project, if we put on the lens of information entropy, you may have something like this:

A verification pyramid: high‑level product spec at the top, a large layer of automated tests (BDD/E2E/acceptance/regression) in the middle that continuously checks behavior, and the implementation code at the bottom.
The software product spec is at the top, the middle is tons of automatic tests, and finally the bottom is the code. While some people would love to see the automatic testing code as, well, just code, I prefer to see it more as software spec. Because it ensures the behavior of the software. What is even better? It can be done automatically.
For some software projects, they may not have much of the spec written in plain English, but they have intensive spec written as automatic test cases. There are many interesting well‑known test suites, such as:
- JVM / Java SE - JCK (TCK for Java SE compatibility)
- SQLite - TCL test suite / test runner and sqllogictest (plus TH3, their proprietary harness)
- Web browsers - Web Platform Tests (WPT)
- Android - Compatibility Test Suite (CTS)
- Kubernetes - Sonobuoy conformance tests
- Graphics APIs - Khronos Vulkan/OpenGL conformance tests (VK-GL-CTS)
The test cases provide a huge amount of entropy and reduce a great amount of software uncertainty. In the era of AI‑assisted programming, implementation details are still very important, but compared to a robust way to define the software and verify it, the value proposition has shifted from the actual code implementation to the verifiable spec.
Anthropic’s compiler experiment
Anthropic ran an experiment to have LLMs generate a compiler and claimed that it’s from scratch (not really) and showed that it can compile the Linux kernel (Building a C compiler with a team of parallel Claudes). The reason they can do it is not because of how smart the LLM is, it is because the software is already well defined by the intensive testing suites provided by the open‑source compiler community, such as the GCC torture tests (and similar compiler test suites). And even if it works, the binary executable performance is still worse than GCC/Clang in many cases, especially without deep optimization work. That is because the entropy that defines performant compiling behavior is not captured in the tests, and LLMs do not understand what makes compiled binary code run fast.

A chimpanzee seated at a typewriter. Credit: New York Zoological Society, circa 1906, Public Domain (via Wikimedia Commons: Chimpanzee seated at typewriter).
{kind=link}
You see, that is the power of having an intensive testing suite carrying a massive amount of software spec entropy, making it possible even for LLMs to generate code that can compile the Linux kernel. This is basically the infinite monkey theorem: given infinite time, a monkey randomly hitting keys on a typewriter will almost surely type the complete works of Shakespeare. With test cases detailed enough, given enough monkeys and time, they can also generate code to pass those tests. Certainly using LLMs has reduced the searching space, plus the compiler code is already part of their training data. Also, humans still made architecture decisions and constrained the problem. But the key enabler is the same: intensive verification (tests) that pins down behavior tightly enough for automation to converge.
Interesting side note: people noticed that the compiler seems to reproduce a bunch of very specific mistakes that match bugs in small open-source C compilers (e.g. chibicc), which suggests it is likely copying/rewriting patterns from its training data rather than “discovering” everything from first principles (see: Hunting for traces of chibicc in Claude's C compiler).
Cursor’s browser experiment
Cursor did a similar experiment, but they built a browser instead (Scaling long-running autonomous coding). After spending trillions of tokens, they had something that barely compiles. The project was later criticized for relying heavily on existing open‑source components (for example Servo and QuickJS) rather than being “from scratch” (see: The Register and the related HN thread). And even if they made anything that looks like it works, it would mostly be because they are using the existing intensive testing cases from existing open‑source browsers.
Cloudflare’s Next.JS rebuild
Yet another interesting and relatively successful case is Cloudflare rewriting Next.JS (How we rebuilt Next.js with AI in one week). Once again, they are using (and explicitly porting) intensive test cases from the Next.js project to verify the AI-generated code works, with some manual architecture work (Cloudflare notes they “ported tests directly from their suite” in How we rebuilt Next.js with AI in one week). The end result outperforms the original project. Is it impressive? Certainly it is. Is LLM going to replace software engineers? Obviously not.
TDD and BDD may make a huge comeback
Now, you see so many examples; they all share the same factor: they all have intensive test cases carrying a huge amount of the verifiable spec. This shows you how important software verification is, particularly in the AI‑assisted programming era. It also shows you that with enough high-quality entropy provided by an automatic test suite, even LLMs can generate software that works. For these projects, they actually chose to do them probably only because there are existing test cases. But what if you do not have the test cases to begin with? Now it begs the interesting question, how do you come up with an intensive test suite from nowhere? It is still the same problem as where the entropy about the software spec is coming from, and how detailed it should go to make it behave exactly like you need.
Interestingly, in the industry, some people advocated strongly for TDD (test‑driven development) and BDD (behavior‑driven development) in the past. I like the idea of having test cases before implementing code, because it is like defining how the software behaves first. But you can only go so far with an imaginary system and thinking about how it could behave. After you build the system, there will always be unexpected details popping up, and you need to go back and revise your spec, i.e., your test cases. Thus, there is still no running away from understanding the software, i.e., you still need a software engineer to help you do so.
Back in 2023, I envisioned on X that TDD/BDD would become a big thing again with AI‑assisted programming.
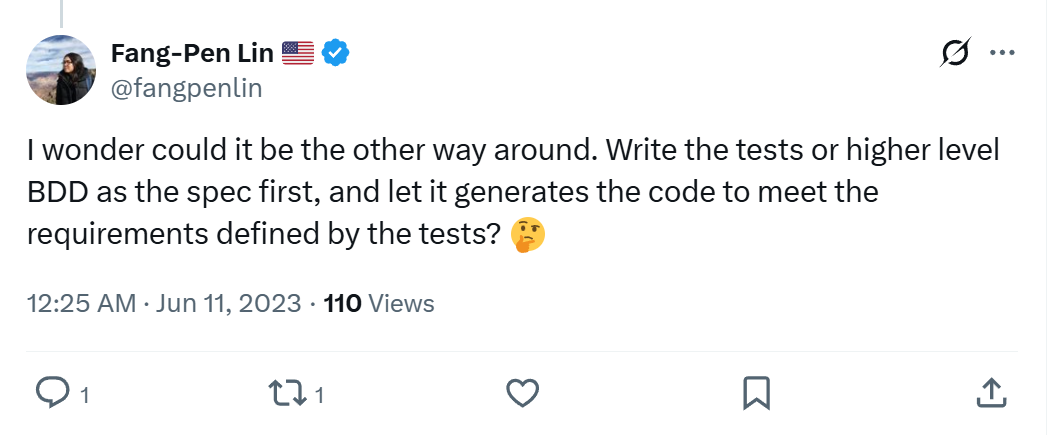
My 2023 X post: use BDD as the spec and generate code.
Today, seeing the examples mentioned above, I more firmly believe that approaches similar to TDD/BDD will make a huge comeback. It is not a solved problem, and unlikely to become one: because of the sheer amount of entropy the test cases need to carry, it cannot come out of nowhere. Someone needs to provide it. And it remains a challenging problem, there is no way you can get rid of software engineers. LLMs can help generate test cases, but someone still needs to drive it and ensure it is testing the actual desired behavior. It is like:
Hey, write tests to ensure the software is correct
I would show you this meme:
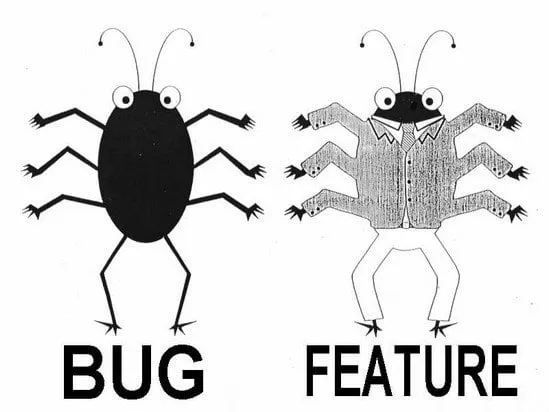
The classic "bug or feature?" ambiguity: without a precise spec, you can't even tell whether behavior is wrong or intended, and "write tests to ensure correctness" becomes "define what correct means" first.
And say
Well, define what is correct 🤣
You see? It still needs entropy from you regardless.
The implication of the value proposition shifting from implementation to verifiable software spec (for tech companies and open-source communities)
The real interesting case to me is Cloudflare’s Next.JS port. With extensive test cases carrying the entropy, it seems like you can throw away the implementation code and rewrite from the ground up quickly. What does it mean to the tech companies and the open source communities? Interestingly, there are some special cases of open-source projects, such as SQLite: they keep some of their most critical test cases secret, for many reasons. If they published those test suites, recreating SQLite would be much easier. For companies running open-source business models, does this mean they also need to keep extensive test cases private, while only keeping the code open-sourced, to avoid a quick clone with LLMs? But that’s a topic for another day.
Final thoughts
There’s much more I’d like to discuss. But this is already a long article. Overall, I think replacing software engineers with LLMs is far more challenging than people think. A productivity boost could displace some software engineers, but not all. And the new demand created by empowered non-technical people will create new opportunities for software engineers.
If you don’t know how to code and an LLM empowers you to build software you couldn’t build before, I’d encourage you to go for it. There’s only upside in your use case. I bet this will create more demand for experienced software engineers, because some people will have something to lose. But if you’re a big tech company making big money from your software, I would do it very carefully if I were one of your stakeholders.
It seems like the leading LLM companies are under heavy pressure to pull more money into the system. So they keep telling a story as big as “replacing all software engineers.” I intentionally use the term LLM instead of AI because the discussion above is specifically about the LLM architecture. At least for LLMs, I think it’s impossible; it’s just nonsense.
Could there be a new model that’s not an LLM? I have no clue. But I highly doubt it. I don’t currently see credible signs of a near-term paradigm shift that removes the spec/verification bottleneck rather than merely accelerating implementation. This belief also aligns with Fred Brooks’s classic idea of “No Silver Bullet”: there isn’t a single breakthrough that gives an order-of-magnitude improvement by itself, especially when the hard part is the essential complexity of specifying what you actually want. Plus, LLMs have absorbed a lot of research resources. There’s little diversity in research directions. I doubt anything fundamentally different will emerge in the short term.
I know many of you can’t wait to throw stones at me for saying the truth LLM companies don’t want to hear. Hey, not so fast. 😅 As I said, I’ve found LLMs very useful in software engineering. And they’ve boosted my productivity a lot. There are patterns I find very effective. And there are anti-patterns they handle poorly. I’ll try to write those up in a separate article. “Vibecoding” is more about ignoring (and accepting) whatever comes out of the model. I prefer to call it AI-assisted programming.
How AI-assisted programming will change the industry is yet another interesting topic. Unlike some people who avoid making predictions, I love making predictions. I’d love to make a statement, then revisit it a few years later to see if I was right or wrong. Of course, I could be wrong. But next time, I might make a better prediction.
That’s it. I hope you found this article helpful. Feel free to leave feedback or questions below. Thanks for taking the time to read.