No, LLM is not going to replace software engineers, here's why
Today, I’d like to share my theory about why LLMs cannot replace software engineers, based on my experience and observations. Who am I to talk about this topic, you may ask. Well, not much, except that I have spent more than two decades of my life programming, almost every single day, long before GPT was a thing. You can check my GitHub profile, but it only captures one decade+ (from when git was a thing), and those are just GitHub repos not including all proprietary repos I have worked on.

More than a decade of GitHub contributions on my public profile. This is only what GitHub can see (public + any private contributions I opted to show), not the proprietary repos I’ve worked in.
These are all organic commits. I never commit a single line of code just to make my GitHub profile look green, because that’s stupid. Before LLMs, I wrote almost all my code keystroke by keystroke. Sounds crazy, right? 🤣
Yep, that’s how things used to be. And it can last for so long only because I truely enjoy programming. I’ve built countless software projects: backend, frontend, mobile, data pipelines, browser extensions, infrastructure as code, and even trained AI models from scratch, and so on. After using LLMs to speed up coding, I have to say: if you use them the right way, they can make you many times faster. But it’s not all sunshine and rainbows, if you rely on them too much, programming becomes painful, and it chips away at your ability to think like an engineer from first principles. I did some soul-searching and found that I still enjoy programming, so I intentionally handwrite code from time to time to keep the muscle strong.
Like many of my fellow software engineers, I used to panic a bit when I saw machines spitting out code like crazy fast. Are my experiences from the past two decades all in vain? But the truth is, the more I learn about LLMs, the more I use them, the more I realize it is not like many claim, that they could replace software engineers in 12 months. I didn’t buy into the hype, but at the same time, I don’t feel desperate. Instead, I feel cautiously optimistic about the future of software engineering.
Because, simply put: no. Despite many tech companies committing collective suicide by drinking the Kool-Aid, LLMs are not going to replace software engineers. Most people confuse the idea of coding with software engineering. LLMs surely have a huge impact on the software industry: they speed up many things greatly, but like any tool, there is a trade-off. Now the cost of making sloppy software goes down almost to zero, but that does not mean software engineers will disappear. Let’s see why I think it is this way.
...
Read the full articleManufacturing as Code is the Future, and the Future is Now
Since I started my journey with 3D printing, I have built and shared dozens of 3D printable models to the public. Surely, TinyRack is one of them. You can find them on my MakerWorld profile here or on my Printables profile here.

My Printables and MakerWorld profiles showing dozens of 3D printable models
So far, I have really enjoyed the process of designing and printing the models. If there’s anything I’ve experienced that feels most like it came out of science fiction, it’s 3D printing technology. When you realize that the physical form of objects can be defined by digital bits, it opens up unbounded possibilities for what we can do with the technology.
The more I design and print, the more I realize that while the printing process takes time, it runs smoothly in the background. But for design, it’s a whole different story. More often than not, it takes a huge amount of effort and countless iterations to design even for a simple snap-fit part. I often get lost when working with different revisions of the same part with slight differences. As printing technology becomes more and more mature, the bottleneck is not the printing anymore, it’s the design instead.
As a software engineer, I get very comfortable with writing code to define the behavior of a system. Setting up the CI/CD pipeline to automate the build and deployment process is also a common practice. While I work on my 3D printing projects, none of those exist. Then I wondered, given that now bits can shape atoms, why not use the same approach to build software for the physical world?
With that in mind, I spent the past few weeks building a prototype of a GitHub-like platform for manufacturing, called MakerRepo. Today I am very excited to announce that the project is now online and has entered the beta testing phase for the public. 😄🎉
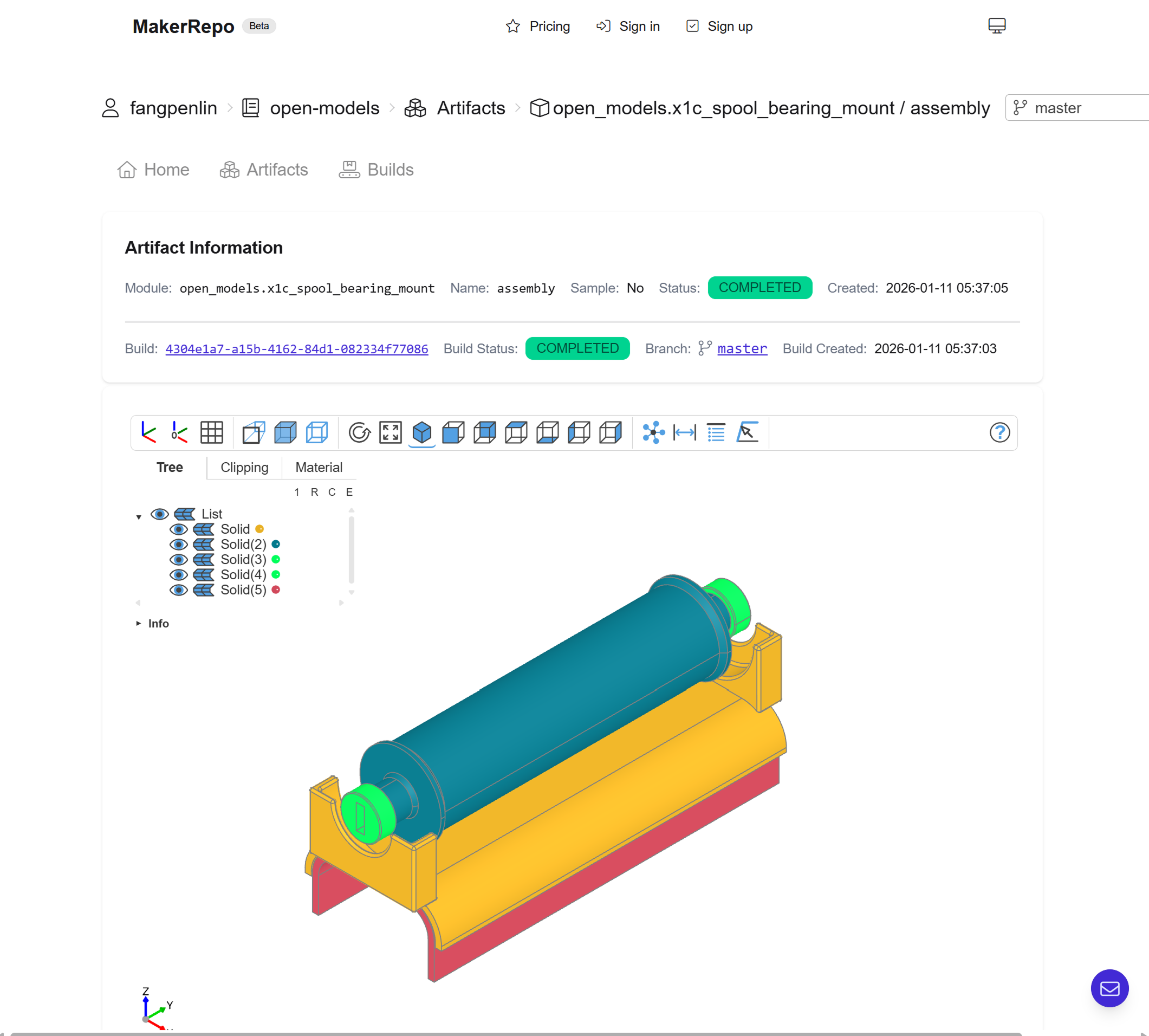
Screenshot of MakerRepo artifacts viewer featuring a 3D model of a part
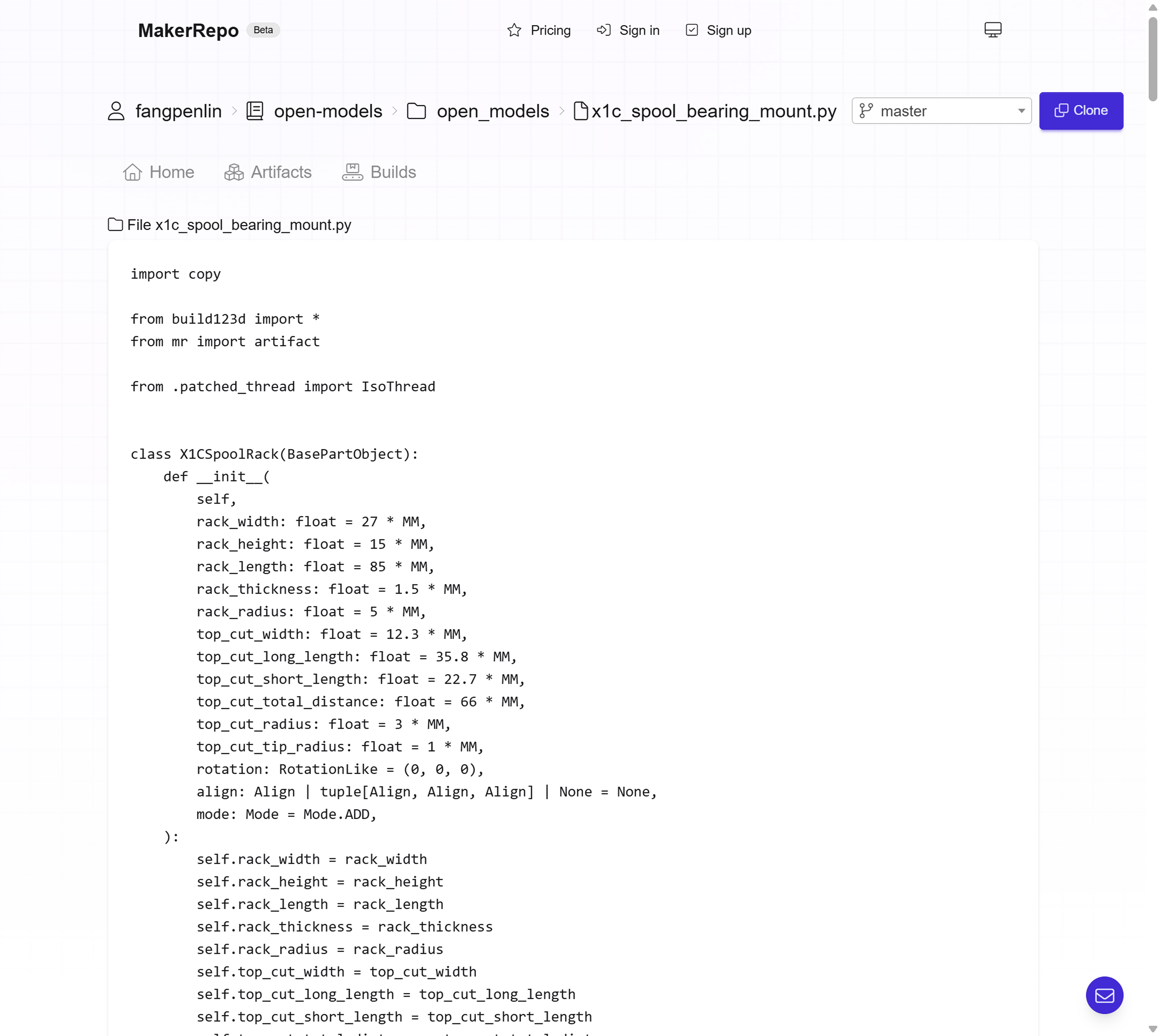
Screenshot of MakerRepo code viewer featuring a Python code file for generating a 3D model with Build123D with an "artifact" decorator
...
Read the full articleTinyRack - A 3D printable modular rack for mini servers
Update: This is the second article in the CADing and 3D printing series. You can read other articles here:
In my previous article, I’ve shared my journey of 3D printing and learning CAD from the perspective of a software engineer. As mentioned in the article, I really wanted to build a server rack for my bare metal Kubernetes cluster as seen in this article. Recently, I finally got some time to actually print some projects I have designed so far. Today, I am excited to introduce what I’ve built - TinyRack, a modular rack for mini servers!

TinyRack with my mini PC cluster
I imagine many people would enjoy a server rack designed specifically for mini servers, given how popular homelabs have become in recent years, so I share my models under an open license. You can download all the models from TinyRack.io and print them yourself, or you can also purchase them on the website.
...
Read the full articleContinual learning with the Marketplace algorithm: model learns new data through inference, not training
Have you ever wondered why machines need a dedicated training process while humans can learn from experience? I wondered the same thing for a long time. Today, I’d like to introduce continual learning with the Marketplace algorithm, which demonstrates the possibility of machines learning new things by simply doing!
This is the third article in the Marketplace algorithm series. Please read the first article and second article for details on the Marketplace algorithm. Last week, I published the second article, which discusses using all the probes to compose the best parameter delta. It was a lot of fun! 😄
However, training a model like a normal training process is not the most exciting application of the Marketplace algorithm. The previous articles were just appetizers; the main course is here. The most intriguing application of the Marketplace algorithm is continual learning. I had this idea almost immediately after developing the Marketplace algorithm. After running through the concept in my mind, I believed it was feasible. So, I spent a few days implementing it, and it worked! It still has a long way to go, but it already shows great potential.
The experiment’s design is straightforward. First, I trained the beautiful MNIST model from Tinygrad using the Marketplace V2 algorithm and the digits dataset for 2,000 steps, achieving 96% accuracy on the validation dataset. Next, I took the trained model, simulated the inference process, and added class 3 (dress) from the Fashion MNIST dataset, mixing these images with the digits dataset to allow the model to classify them.
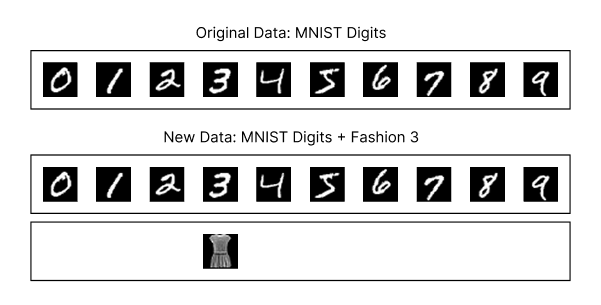
A diagram showing the original MNIST digits dataset and the new dataset, which combines the MNIST digits dataset with class 3 (dress) from the Fashion MNIST dataset.
I applied the Marketplace algorithm to enable the model to continually learn the new dress images gradually with each step. The goal was to determine whether the model could learn the new dress images primarily through inference, without dedicated training, while still classifying digits correctly most of the time to provide business value. Here’s the result:
As shown, the model gradually learns the new dress images over several steps while maintaining its ability to classify digits correctly most of the time. These steps involve only inference, with no dedicated training process!
The implications of this technology are tremendous. I believe the future of machine learning lies in learning rather than training. Companies that master this approach in production will gain a significant advantage because their models improve as more people use them, quickly and without much additional cost. As the model improves, it attracts more users, creating a flywheel effect: the more it’s used, the better it becomes. Best of all, this approach requires almost no additional computational cost for training. Of course, this is just a proof of concept, and there are still many improvements to make and challenges to overcome. Nevertheless, I’m thrilled about the possibilities of continual learning. Today, I’m excited to share my first take on continual learning with the Marketplace algorithm.
...
Read the full article