Marketplace V2 is all you need: A training algorithm on par with backprop that needs only forward pass
Update: Third article is here, Continual Learning with Marketplace: Model Learns New Data with Mostly Inference
Two weeks ago, I published an article, Marketplace: My first attempt at training without backprop on GPU efficiently. To my surprise, it received far more positive feedback than I expected. I was thrilled that people found my research project interesting, and I greatly appreciate the kind words from readers.
Curious about how far I could push this idea, I spent another two weeks improving it. Initially, my research focused on enhancing the scalability of the Marketplace algorithm. I implemented seed-based random number generation for each vendor’s weights, as mentioned in the previous article. I also explored other ideas to improve the Marketplace algorithm, such as using a second forward pass to determine the optimal learning rate. However, exploring permutations of the loss outputs to compose a better overall delta, accounting for both good and bad outcomes, truly blew my mind 🤯.
The performance is now on par with backpropagation in certain configurations. Here’s the comparison with backpropagation plus Stochastic Gradient Descent (SGD) as the optimizer:

A diagram with 50% smoothing shows the comparison of the validation accuracy between the Marketplace V2, V1 algorithms and the backprop with SGD as the optimizer based on different learning rates. The Marketplace V2 algorithm outperforms the Marketplace V1 algorithm greatly and the backprop with SGD as the optimizer at 1e-3 learning rate. It only lose to the backprop with SGD as the optimizer at 3e-3 learning rate and 7e-3 learning rate. While backprop with SGD as the optimizer is still better, but I believe with hyperparameter tuning, the Marketplace V2 algorithm can at least match it.

A diagram with 50% smoothing shows the comparison of the loss between the Marketplace V2, V1 algorithms and the backprop with SGD as the optimizer based on different learning rates. The Marketplace V2 algorithm outperforms the Marketplace V1 algorithm greatly and the backprop with SGD as the optimizer at 1e-3 learning rate and 3e-3 learning rate in later steps. It only lose to the backprop with SGD as the optimizer at 7e-3 learning rate. While backprop with SGD as the optimizer is still better, but I believe with hyperparameter tuning, the Marketplace V2 algorithm can at least match it.
I believe my research has a significant potential to revolutionize the machine learning training process. Today, I’m excited to share the improvements to the Marketplace algorithm, which I call the Marketplace V2 algorithm.
...
Read the full articleMarketplace: my first attempt at training without backprop on GPU efficiently
Update: Please read the second article for the details of the V2 algorithm. Also the third article, Continual Learning with Marketplace: Model Learns New Data with Mostly Inference, introduces the continual learning with the Marketplace algorithm.
If you’ve read my previous articles, you know I’m a big fan of first-principles thinking. I’ve mentioned many times that I want to eliminate backpropagation. Many people think I’m crazy and assume I must be joking. But no, I’m serious. I thought about the problem from time to time. Recently, I came up with an idea that could potentially work. I spent two weeks implementing it and running experiments, and it worked! While this is just a baby step, there are still many things to improve, but at least I think it’s an interesting idea that could be worth exploring and sharing. Today, I would like to share my approach to training without backpropagation on GPUs efficiently.

A diagram shows the validation accuracy of a small MNIST CNN model training process without using backpropagation.

A diagram shows the loss of a small MNIST CNN model training process without using backpropagation.
...
Read the full articleCakeLens V5, the AI-gen video detection model is now open-sourced!
Today, I’m excited to announce that the CakeLens v5 AI-generated video detection model is now open-source! Why open-source, you might ask? Well, the CakeLens project serves multiple purposes for me. (For more background, see my earlier article: I built an AI-gen detection model for videos, here’s what I learned.) The most critical one was to teach myself how to build a machine learning-powered product from end to end, including data collection, labeling, model design, training, and inference. It has already achieved that goal.
Beyond personal learning, I hoped CakeLens could uncover some business value. However, the reality is that most users don’t care much whether the funny videos they see online are AI-generated or not. In an enterprise context, though, detecting AI-generated content is more critical. For example, ID verification services often require users to hold an ID and take a photo or short video. What happens if scammers generate realistic fake photos or videos in the future? What if job candidates alter their face or voice? These issues are already happening.

Screenshot from a LinkedIn post (source) showing a job interview conducted via video call, where the candidate's face has been swapped using AI-generated imagery. This highlights real-world cases of AI-generated content being used for identity fraud in professional settings.
I believe this represents a new market category yet to be fully addressed. CakeLens is my initial step into exploring this space.
While the CakeLens v5 model for detecting AI-generated videos works reasonably well with a limited dataset (77% precision, 74% recall with 50% threshold), its accuracy is still too low for enterprise use cases. I searched for similar open-source models but found none. I guess cool kids are mostly focused on large language models (LLMs) right now. Although this isn’t a flashy moonshot project, I believe open-sourcing CakeLens v5 offers educational value to others. So, here we are!
...
Read the full articleTwo AMD 7900XTX GPUs in a Tinygrad-Based Training Workstation with Peer-to-Peer PCIe Communication
I’ve been diving into machine learning projects lately, and I enjoy it a lot. However, one thing bothers me: I lack the computing power to test many interesting ideas. In my previous article for CakeLens, I designed and trained a model to detect AI-generated videos. But due to limited local computing power, I had to rent H100/A100 GPUs from Modal to experiment with different approaches. And it’s not cheap:
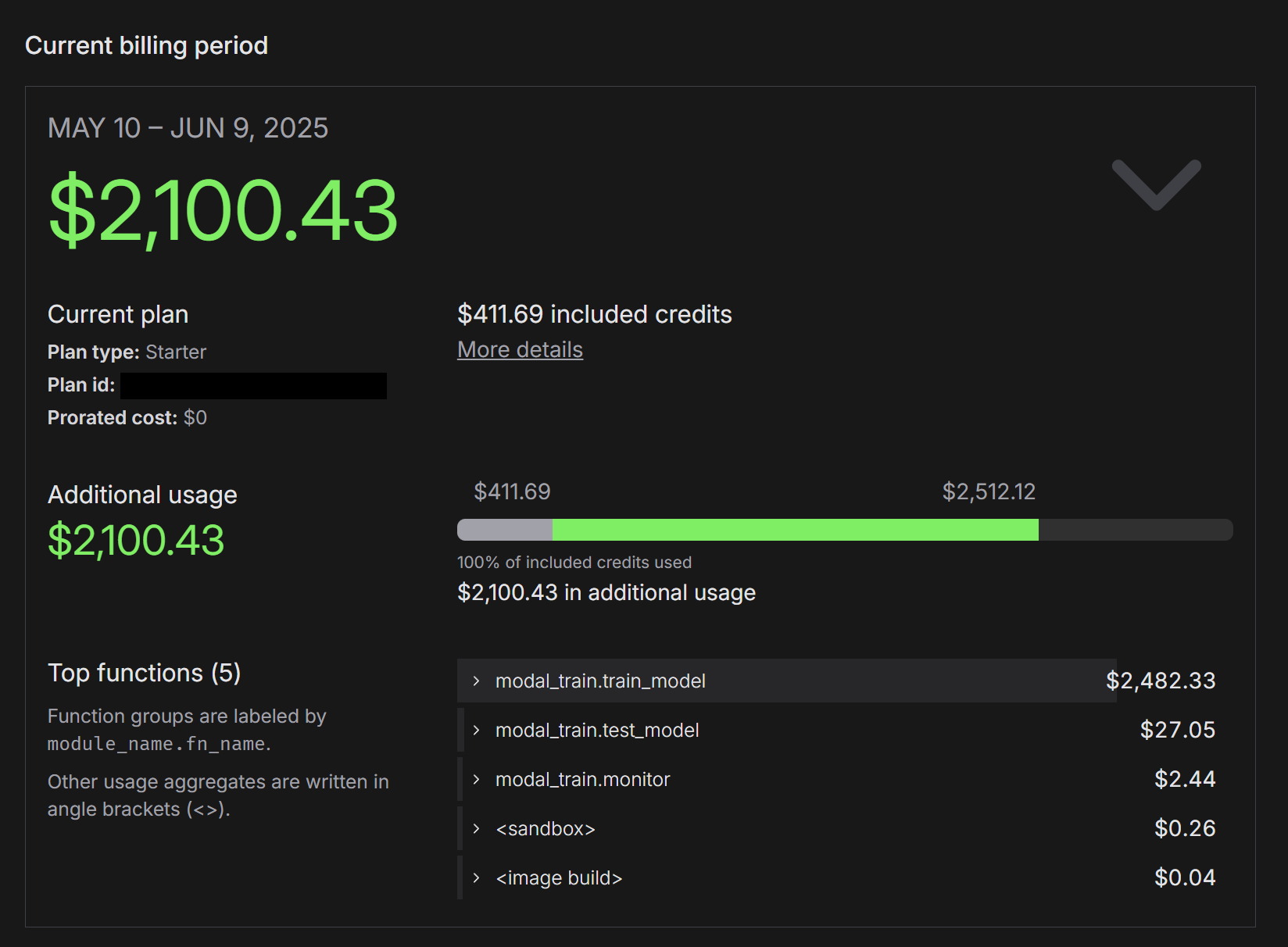
Screenshot of Modal's billing dashboard showing the total cost as $2.1K
My PC has an RTX 4090, so I could run training locally. However, memory constraints make it painful to train larger models. Even when a model fits on the GPU, the intensive computation consumes all GPU resources, rendering my PC unusable. To solve this, I need more local computing power to run machine learning experiments without breaking the bank.
My first idea was to buy another RTX 4090 or perhaps an RTX 5090. I checked prices online and was shocked. I bought my current 4090 for around $2,000 USD, but now they’re selling for $3,600 on Amazon. That’s insane! 🤯
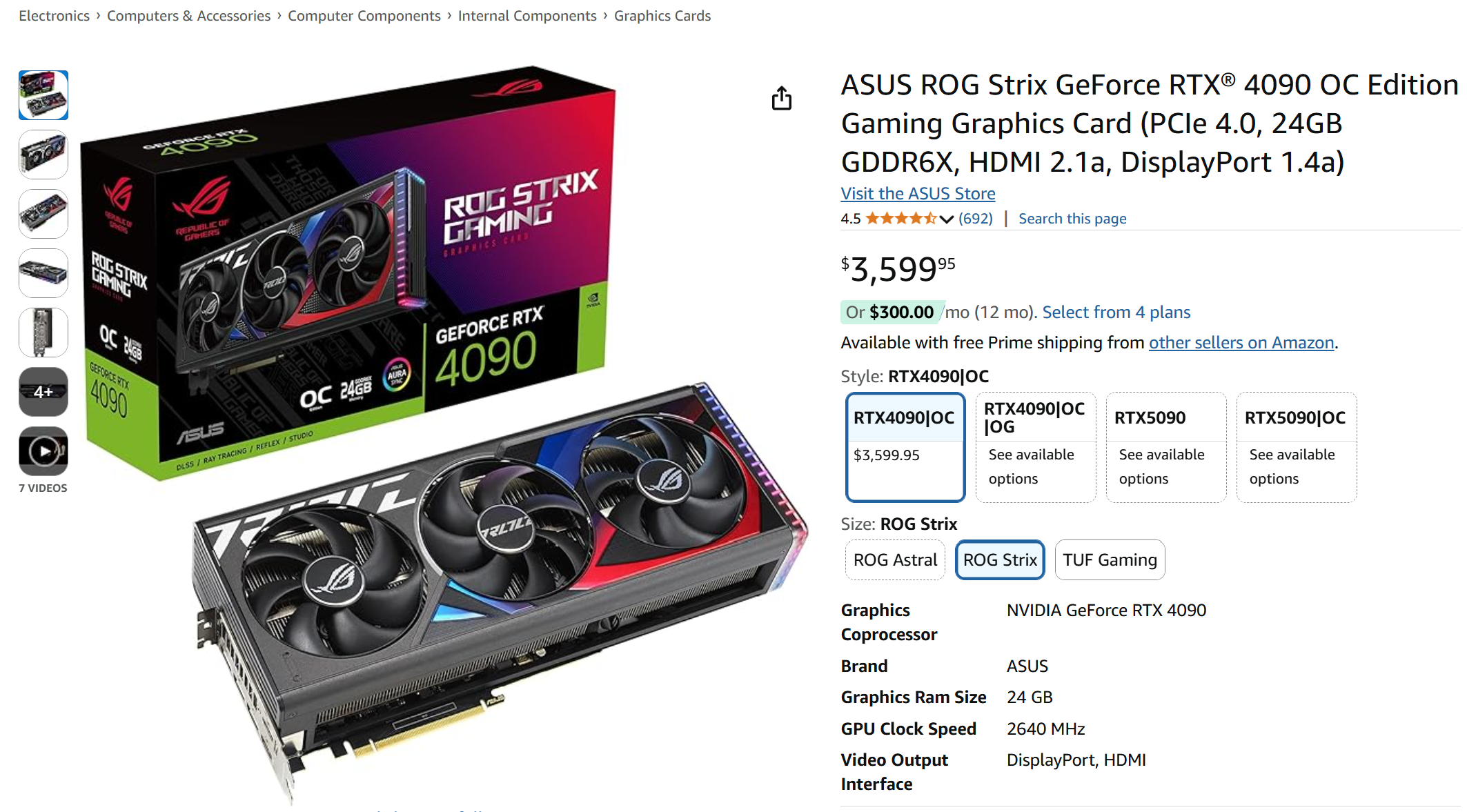
Screenshot of Amazon product page, featuring Asus ROG Strix RTX 4090 GPU selling at $3,599.95
Curious about the cost of an H100 for my home office, I checked its price:
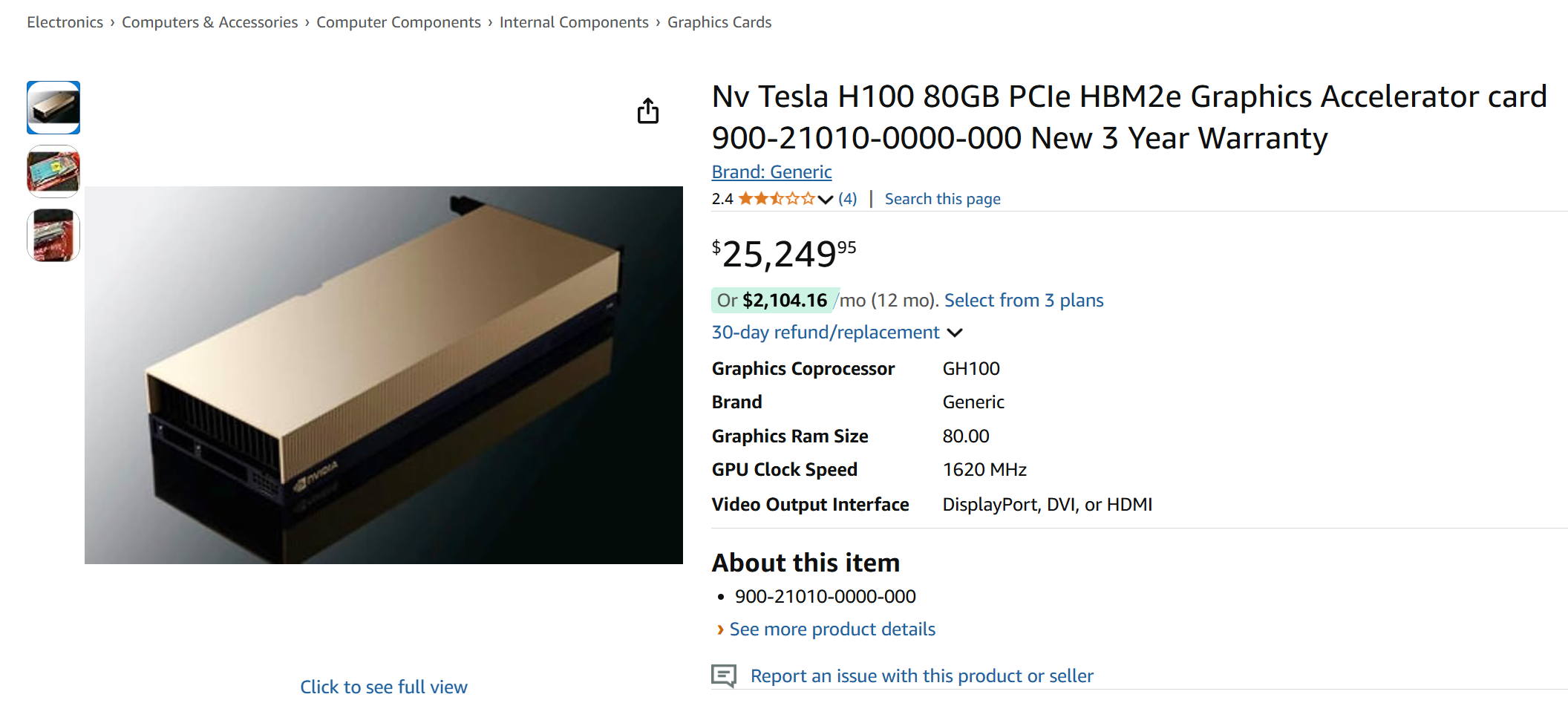
Screenshot of Amazon product page, featuring Nvidia Tesla H100 GPU selling at $25,249.95
Heh, you know what? I’m not planning to sell two KDNYs I have accumulated just yet 😅.
I don’t have the budget for more Nvidia GPUs right now, but I still want a local setup to experiment at a lower cost. One day, while browsing X, I found a post by Tinygrad showcasing their gradient functions defined in just 40 lines of code.
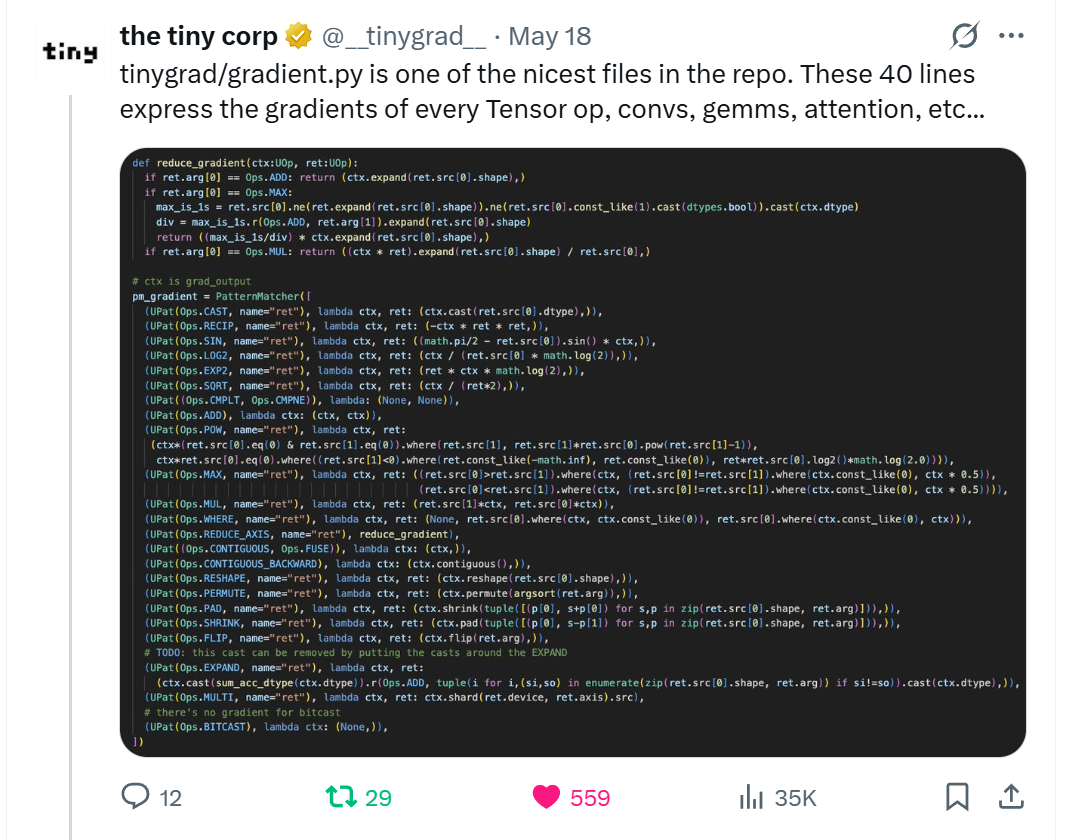
A X post by @__tinygrad__ showcasing gradients for backprop defined in just 40 lines
I tried it, and it was impressive—no dependencies, just an instant install with uv.
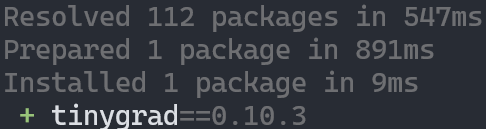
Screenshot of installing tinygrad with uv shows it only takes 9ms
After researching further, I really liked Tinygrad’s concept. It’s like the RISC (Reduced Instruction Set Computer) of machine learning, while PyTorch feels more like CISC (complex instruction set computer). I appreciate its clean, minimalist design, and it seems to support AMD GPUs well.
This made me wonder: why does everyone say Nvidia GPUs are the go-to for machine learning? They claim Nvidia’s strength lies in its software. Hmm, is that true? 🤔 Or, as some might say, is it a skill issue? 🤣
I’m not sure, but I wanted to find out. I’m curious about Tinygrad’s pre-built AMD training workstation. It’s tempting, but it’s outside the budget I can allocate, and it’s too bulky for my home office.

Screenshot of Tinybox, a pre-built machine learning work station by the tiny corp featuring AMD and Nvidia GPU options. The AMD option is selling at $15,000 USD
Looked at the GPUs they are using, the AMD 7900XTX seemed mature. Best of all, the price was reasonable—just $1,100:
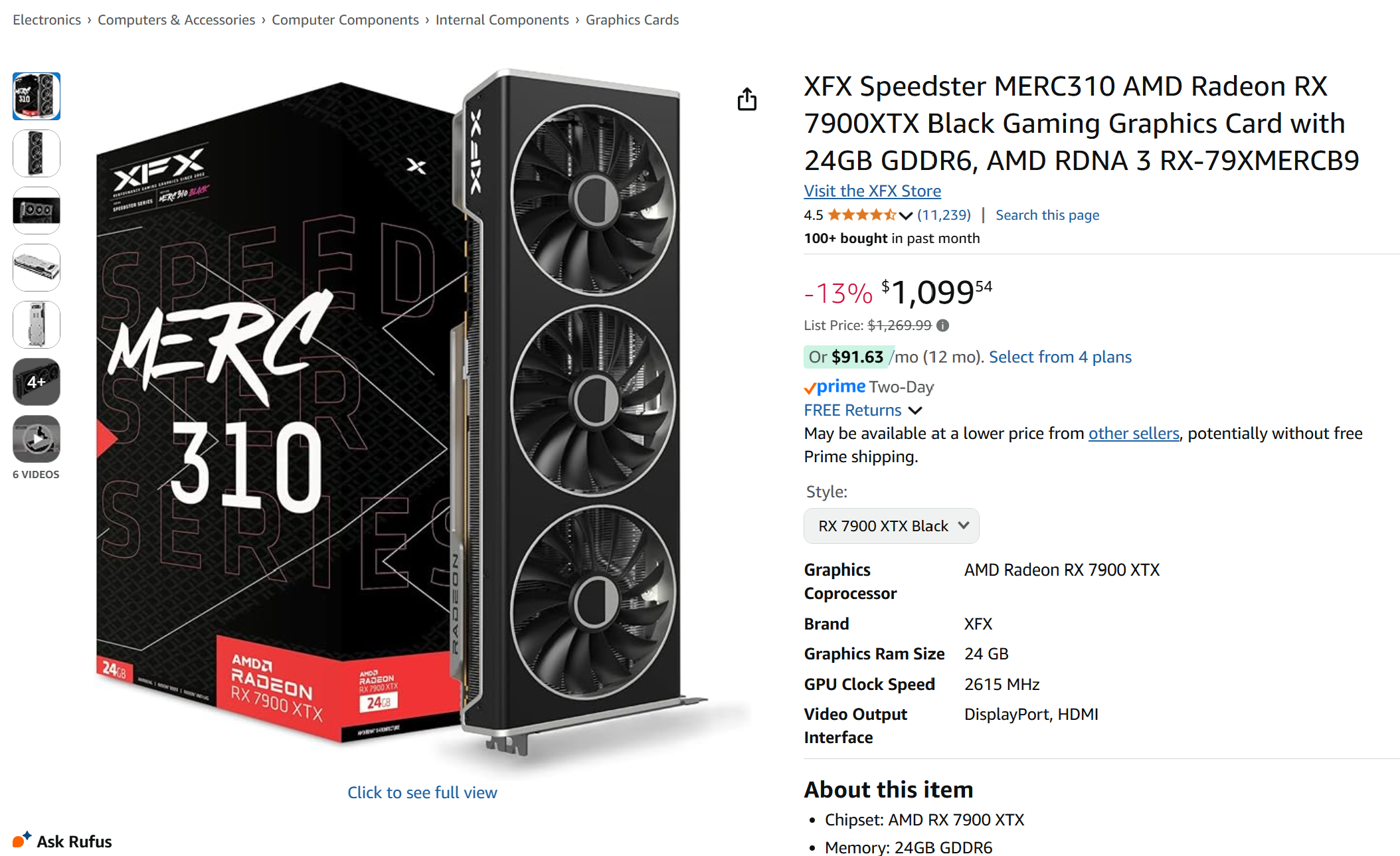
Screenshot of Amazon product page, featuring XFX AMD Radeon RX 7900XTX GPU selling at $1,099.54
I had a retired PC, so I quickly purchased two 7900XTX GPUs:

Two boxes of XFX AMD Radeon RX 7900XTX GPUs
I did my best with cable management:

Two XFX AMD Radeon RX 7900XTX GPUs in an open PC case with PCI power cables connected to them
It was time-consuming, and I tried 😅
...
Read the full article